MySQL高级
MySQL高级
一、三范式
1、什么是三范式
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
2、数据冗余
数据冗余是指数据之间的重复,也可以说是同一数据存储在不同数据文件中的现象
3、范式的划分
根据数据库冗余的大小,目前关系型数据库有六种范式,各种范式呈递次规范,越高的范式数据库冗余越小。
六种范式:
第一范式(1NF)
第二范式(2NF)
第三范式(3NF)
巴斯-科德范式(BCNF)
第四范式 ( 4NF)
第五范式(5NF,又称完美范式)
一般遵循 前三种范式即可
4、一范式
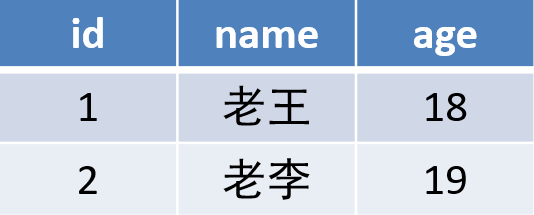
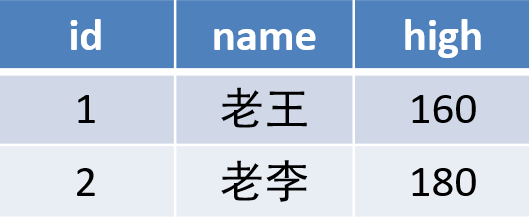
第一范式(1NF): 强调的是字段的原子性,即一个字段不能够再分成其他几个字段。

这种表结构设计就没有达到 1NF,要符合 1NF 我们只需把字段拆分,即:把 contact 字段拆分成 name 、tel、addr 等字段。

5、二范式
第二范式(2NF): 满足 1NF的基础上,另外包含两部分内容
一是表必须有一个主键
二是非主键字段必须完全依赖于主键,而不能只依赖于主键的一部分

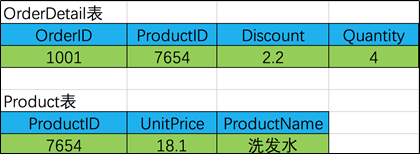
OrderDetail表的主键是什么?
主键的定义:能够确定唯一一行记录的特殊字段

create table test (
name varchar(19),
id int,
primary key (name,id)
)
这里有主键由OrderID和ProductID共同组成
同时 UnitPrice 和 ProductName 这里两个字段 与ProductID的从属关系强于他们同OrderID的从属关系
6、三范式
第三范式(3NF): 满足 2NF
另外非主键字段必须直接依赖于主键,不能存在传递依赖。
即不能存在:非主键字段 A 依赖于非主键字段 B,非主键字段 B 依赖于主键的情况。

因为 OrderDate,CustomerID,CustomerName,CustomerAddr,CustomerCity 等非主键字段都完全依赖于主键(OrderID),所以符合 2NF。
不过问题是 CustomerName,CustomerAddr,CustomerCity 直接依赖的是 CustomerID(非主键列),而不是直接依赖于主键,它是通过传递才依赖于主键,所以不符合 3NF。
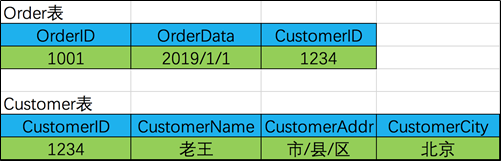
把【Order】表拆分为【Order】(OrderID,OrderDate,CustomerID)和【Customer】(CustomerID,CustomerName,CustomerAddr,CustomerCity)从而达到 3NF。
7、知识要点
范式:
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
三范式:
第一范式(1NF): 强调的是列的原子性,即列不能够再分成其他几列。
第二范式(2NF): 满足 1NF,另外包含两部分内容,一是表必须有一个主键;
二是非主键字段 必须完全依赖于主键,而不能只依赖于主键的一部分。
第三范式(3NF): 满足 2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。
即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。
二、E-R模型及表间关系
1、E-R模型的使用场景
对于大型公司开发项目,我们需要根据产品经理的设计,先使用建模工具, 如:power designer,db desinger等这些软件来画出实体-关系模型(E-R模型)
然后根据三范式设计数据库表结构
2、E-R模型
E-R模型即实体-关系模型
E-R模型就是描述数据库存储数据的结构模型
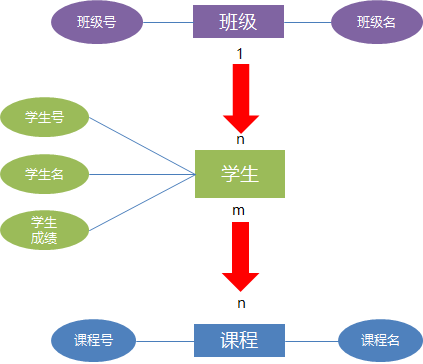
3、三种关系
表现形式
实体: 用矩形表示,并标注实体名称
属性: 用椭圆表示,并标注属性名称
关系: 用菱形表示,并标注关系名称
E-R模型中的三种关系
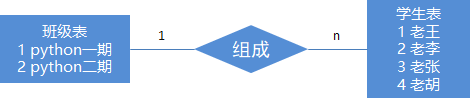
一对一

一对多(1-n)
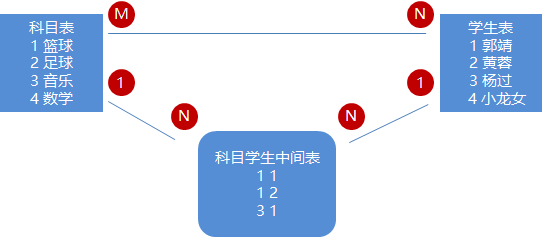
多对多(m-n)
4、知识要点
E-R模型由 实体、属性、实体之间的关系构成,主要用来描述数据库中表之间的关系和表结构。
开发流程是先画出E-R模型,然后根据三范式设计数据库中的表结构
三、PyMySQL
前提
提前安装MySQL数据库(可以使用Linux系统的,也可以使用Windows版本,如小皮面板)
1、为什么要学习PyMySQL
如何实现将100000条数据插入到MySQL数据库?
答案:
如果使用之前学习的MySQL客户端来完成这个操作,那么这个工作量无疑是巨大的,我们可以通过使用程序代码的方式去连接MySQL数据库,然后对MySQL数据库进行增删改查的方式,实现100000条数据的插入,像这样使用代码的方式操作数据库就称为数据库编程。
2、安装PyMySQL模块
安装PyMySQL:
# pip install pymysql卸载PyMySQL:
# pip uninstall pymysql3、PyMySQL的使用(七步走)
☆ 导入 pymysql 包
import pymysql☆ 创建连接对象
调用pymysql模块中的connect()函数来创建连接对象,代码如下:
conn=connect(参数列表)
* 参数host:连接的mysql主机,如果本机是'localhost'
* 参数port:连接的mysql主机的端口,默认是3306
* 参数user:连接的用户名
* 参数password:连接的密码
* 参数database:数据库的名称
* 参数charset:通信采用的编码方式,推荐使用utf8连接对象操作说明:
- 关闭连接 conn.close()
- 提交数据 conn.commit()
- 撤销数据 conn.rollback()
☆ 获取游标对象
获取游标对象的目标就是要执行sql语句,完成对数据库的增、删、改、查操作。代码如下:
# 调用连接对象的cursor()方法获取游标对象
cur =conn.cursor()游标操作说明:
- 使用游标执行SQL语句: execute(operation [parameters ]) 执行SQL语句,返回受影响的行数,主要用于执行insert、update、delete、select等语句
- 获取查询结果集中的一条数据:cur.fetchone()返回一个元组, 如 (1,'张三')
- 获取查询结果集中的所有数据: cur.fetchall()返回一个元组,如((1,'张三'),(2,'李四'))
- 关闭游标: cur.close(),表示和数据库操作完成
☆ pymysql完成数据的查询操作
import pymysql
# 创建连接对象
conn = pymysql.connect(host='localhost', port=3306, user='root', password='mysql',database='db_itheima', charset='utf8')
# 获取游标对象
cursor = conn.cursor()
# 查询 SQL 语句
sql = "select * from students;"
# 执行 SQL 语句 返回值就是 SQL 语句在执行过程中影响的行数
row_count = cursor.execute(sql)
print("SQL 语句执行影响的行数%d" % row_count)
# 取出结果集中一行数据, 例如:(1, '张三')
# print(cursor.fetchone())
# 取出结果集中的所有数据, 例如:((1, '张三'), (2, '李四'), (3, '王五'))
for line in cursor.fetchall():
print(line)
# 关闭游标
cursor.close()
# 关闭连接
conn.close()☆ pymysql完成对数据的增删改
import pymysql
# 创建连接对象
conn = pymysql.connect(host='localhost', port=3306, user='root', password='mysql',database='db_itheima', charset='utf8')
# 获取游标对象
cursor = conn.cursor()
try:
# 添加 SQL 语句
# sql = "insert into students(name) values('刘璐'), ('王美丽');"
# 删除 SQ L语句
# sql = "delete from students where id = 5;"
# 修改 SQL 语句
sql = "update students set name = '王铁蛋' where id = 6;"
# 执行 SQL 语句
row_count = cursor.execute(sql)
print("SQL 语句执行影响的行数%d" % row_count)
# 提交数据到数据库
conn.commit()
except Exception as e:
# 回滚数据, 即撤销刚刚的SQL语句操作
conn.rollback()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()注:PyMySQL是基于事务进行操作的,所以在数据库增删改操作时,必须通过conn.commit() 方法将事务操作提交到数据库,如果事务操作没有成功,则可以通过conn.rollback()进行回滚(返回到数据的原始状态)。