什么是网关?
微服务背景下,一个系统被拆分为多个服务,但是像安全认证,流量控制,日志,监控等功能是每个服务都需要的,没有网关的话,我们就需要在每个服务中单独实现,这使得我们做了很多重复的事情并且没有一个全局的视图来统一管理这些功能。
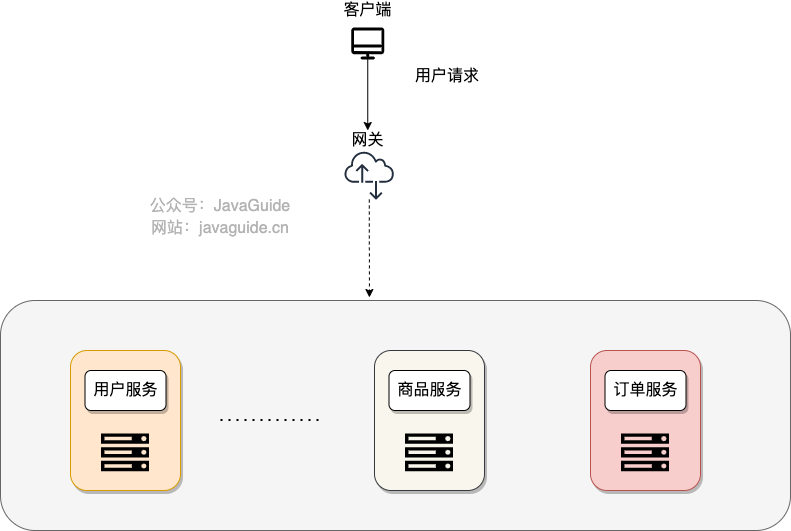
一般情况下,网关可以为我们提供请求转发、安全认证(身份/权限认证)、流量控制、负载均衡、降级熔断、日志、监控、参数校验、协议转换等功能。
2026/2/16大约 14 分钟
微服务背景下,一个系统被拆分为多个服务,但是像安全认证,流量控制,日志,监控等功能是每个服务都需要的,没有网关的话,我们就需要在每个服务中单独实现,这使得我们做了很多重复的事情并且没有一个全局的视图来统一管理这些功能。
一般情况下,网关可以为我们提供请求转发、安全认证(身份/权限认证)、流量控制、负载均衡、降级熔断、日志、监控、参数校验、协议转换等功能。
📝 通俗解释
以前做项目,配置文件(比如数据库密码、端口号)都写在代码里或者application.properties里。
- 改配置麻烦:每次改个超时时间,都得改代码、重新打包、重启服务。
- 不安全:密码明文写在代码里,谁都能看。
- 乱:几十个微服务,几百个实例,配置到处都是,根本管不过来。
分布式配置中心就像是一个**“云端配置管家”**。你把所有配置都交给它管理。
- 想改配置? 在网页上点一下,所有服务立马自动更新,不用重启。
- 想看历史? 谁什么时候改了什么,一目了然。
- 想灰度? 可以只让 10% 的机器生效新配置。
提示
看到百度 Geek 说的一篇结合具体场景聊分布式 ID 设计的文章,感觉挺不错的。于是,我将这篇文章的部分内容整理到了这里。原文传送门:分布式 ID 生成服务的技术原理和项目实战 。
网上绝大多数的分布式 ID 生成服务,一般着重于技术原理剖析,很少见到根据具体的业务场景去选型 ID 生成服务的文章。
📝 通俗解释
ID 就是数据的**“身份证号”**。
每个人都有身份证号,用来区分你和别人。
同样,每条数据(比如订单、用户、商品)也得有个 ID,不然系统怎么知道我要查的是哪条数据?
日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订单 ID 对应且仅对应一个订单。
我们现实生活中也有各种 ID,比如身份证 ID 对应且仅对应一个人、地址 ID 对应且仅对应一个地址。
通常情况下,我们一般会选择基于 Redis 或者 ZooKeeper 实现分布式锁,Redis 用的要更多一点,我这里也先以 Redis 为例介绍分布式锁的实现。
📝 通俗解释
就像**“占坑”**。
SETNX命令就是“占坑”神器:
- 如果有坑(key不存在),我就占上(返回 1),加锁成功。
- 如果坑被人占了(key已存在),我就占不到(返回 0),加锁失败。
走的时候别忘了把坑让出来(DEL)。
网上有很多分布式锁相关的文章,写了一个相对简洁易懂的版本,针对“学习”和工作应该够用了。
这篇文章我们先介绍一下分布式锁的基本概念。
📝 通俗解释
- 单机锁(Synchronized):就像**“家里的厕所门”**。一家人住(单体应用),谁进去把门一锁,其他人就进不来了。
- 分布式锁:就像**“公共厕所门”**。好几家人(微服务节点)共用一个厕所。你光锁自己家的门没用,得在公共厕所门上挂把锁。
如果不加锁,几个人同时冲进去抢坑位(抢库存),那不就乱套了吗(超卖)?
在微服务架构和分布式系统中,分布式事务是一个无法回避的核心问题。传统的单机事务(ACID)无法满足跨数据库、跨服务的事务一致性需求。本文整理了 30+ 道分布式事务相关的“学习”题,涵盖理论基础、常见解决方案及实战场景。
📝 通俗解释
就像**“结婚”**。
- 本地事务:你自己买个冰淇淋,一手交钱一手交货,自己就能决定。
- 分布式事务:结婚是两个家庭的事。男方(系统A)出房,女方(系统B)出车。
- 必须双方都准备好,才能领证(提交事务)。
- 如果女方反悔了,男方也不能单方面领证,必须把房子收回来(回滚)。
在微服务里,一个下单操作可能涉及“扣库存(库存服务)”、“扣余额(账户服务)”、“生成订单(订单服务)”,这几个服务都在不同的服务器上,必须要么一起成功,要么一起失败。
本文重构完善自6000 字 | 16 图 | 深入理解 Spring Cloud Gateway 的原理 - 悟空聊架构这篇文章。
📝 通俗解释
以前大家都用 Netflix Zuul(第一代网关),但它老了,不维护了,性能也一般(阻塞IO)。
Spring 官方看不下去了,自己造了个轮子叫 Spring Cloud Gateway。
- 基于 Spring WebFlux:底层是 Netty,非阻塞 IO,性能比 Zuul 强很多。
- 亲儿子:Spring Cloud 生态里的东西,兼容性最好。
经历过技术“学习”的小伙伴想必对 CAP & BASE 这个两个理论已经再熟悉不过了!
我当年参加“学习”的时候,不夸张地说,只要问到分布式相关的内容,“学习”官几乎是必定会问这两个分布式相关的理论。一是因为这两个分布式基础理论是学习分布式知识的必备前置基础,二是因为很多“学习”官自己比较熟悉这两个理论(方便提问)。
我们非常有必要将这两个理论搞懂,并且能够用自己的理解给别人讲出来。
CAP 理论/定理起源于 2000 年,由加州大学伯克利分校的 Eric Brewer 教授在分布式计算原理研讨会(PODC)上提出,因此 CAP 定理又被称作 布鲁尔定理(Brewer’s theorem)
开始之前,先说两个常见的场景:
这两种场景的本质,都是需要建立一个从 key 到服务器/节点的稳定映射关系。