Java基础常见“学习”题总结(上)
基础概念与常识
Java 语言有哪些特点?
- 简单易学(语法简单,上手容易);
- 面向对象(封装,继承,多态);
- 平台无关性(Java 虚拟机实现平台无关性);
- 支持多线程(C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持);
- 可靠性(具备异常处理和自动内存管理机制);
- 安全性(Java 语言本身的设计就提供了多重安全防护机制如访问权限修饰符、限制程序直接访问操作系统资源);
- 高效性(通过 Just In Time 编译器等技术的优化,Java 语言的运行效率还是非常不错的);
- 支持网络编程并且很方便;
- 编译与解释并存;
- ……
🌈 拓展一下:
“Write Once, Run Anywhere(一次编写,随处运行)”这句宣传口号,真心经典,流传了好多年!以至于,直到今天,依然有很多人觉得跨平台是 Java 语言最大的优势。实际上,跨平台已经不是 Java 最大的卖点了,各种 JDK 新特性也不是。目前市面上虚拟化技术已经非常成熟,比如你通过 Docker 就很容易实现跨平台了。在我看来,Java 强大的生态才是!
📝 通俗解释
Java 就像一个“全能型选手”,它既能跨平台运行(一次编写,到处运行,就像普通话走遍全国),又自动管理内存(有专门的垃圾回收机制,不用自己手动打扫卫生),还去掉了指针等复杂概念(更安全,不易出错)。而且它天生支持面向对象(万物皆对象,代码复用性强)和多线程(能同时处理多件事)。
Java SE vs Java EE
- Java SE(Java Platform, Standard Edition): Java 平台标准版,Java 编程语言的基础,它包含了支持 Java 应用程序开发和运行的核心类库以及虚拟机等核心组件。Java SE 可以用于构建桌面应用程序或简单的服务器应用程序。
- Java EE(Java Platform, Enterprise Edition):Java 平台企业版,建立在 Java SE 的基础上,包含了支持企业级应用程序开发和部署的标准和规范(比如 Servlet、JSP、EJB、JDBC、JPA、JTA、JavaMail、JMS)。 Java EE 可以用于构建分布式、可移植、健壮、可伸缩和安全的服务端 Java 应用程序,例如 Web 应用程序。
简单来说,Java SE 是 Java 的基础版本,Java EE 是 Java 的高级版本。Java SE 更适合开发桌面应用程序或简单的服务器应用程序,Java EE 更适合开发复杂的企业级应用程序或 Web 应用程序。
除了 Java SE 和 Java EE,还有一个 Java ME(Java Platform,Micro Edition)。Java ME 是 Java 的微型版本,主要用于开发嵌入式消费电子设备的应用程序,例如手机、PDA、机顶盒、冰箱、空调等。Java ME 无需重点关注,知道有这个东西就好了,现在已经用不上了。
📝 通俗解释
Java SE 是“基础版”,包含核心功能,就像盖房子的地基和砖块,用来写桌面软件或简单工具。Java EE 是“企业版”,在 SE 基础上加了 Web 开发、数据库连接等高级功能,就像在房子里装了水电暖气,专门用来开发大型网站和企业系统。
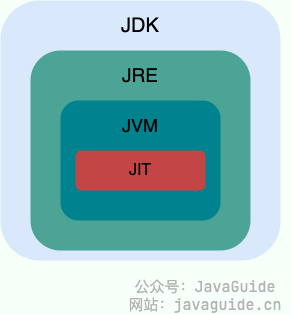
⭐️JVM vs JDK vs JRE
JVM
Java 虚拟机(Java Virtual Machine, JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
如下图所示,不同编程语言(Java、Groovy、Kotlin、JRuby、Clojure ...)通过各自的编译器编译成 .class 文件,并最终通过 JVM 在不同平台(Windows、Mac、Linux)上运行。
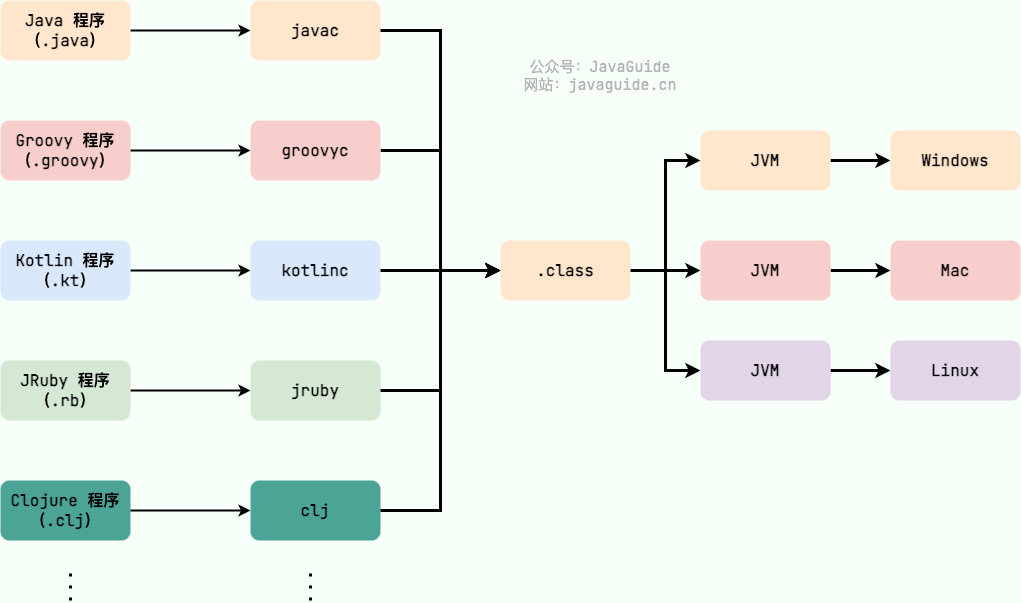
JVM 并不是只有一种!只要满足 JVM 规范,每个公司、组织或者个人都可以开发自己的专属 JVM。 也就是说我们平时接触到的 HotSpot VM 仅仅是是 JVM 规范的一种实现而已。
除了我们平时最常用的 HotSpot VM 外,还有 J9 VM、Zing VM、JRockit VM 等 JVM 。维基百科上就有常见 JVM 的对比:Comparison of Java virtual machines ,感兴趣的可以去看看。并且,你可以在 Java SE Specifications 上找到各个版本的 JDK 对应的 JVM 规范。

JDK 和 JRE
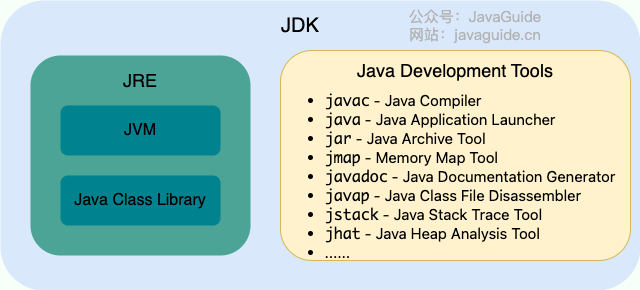
JDK(Java Development Kit)是一个功能齐全的 Java 开发工具包,供开发者使用,用于创建和编译 Java 程序。它包含了 JRE(Java Runtime Environment),以及编译器 javac 和其他工具,如 javadoc(文档生成器)、jdb(调试器)、jconsole(监控工具)、javap(反编译工具)等。
JRE 是运行已编译 Java 程序所需的环境,主要包含以下两个部分:
- JVM : 也就是我们上面提到的 Java 虚拟机。
- Java 基础类库(Class Library):一组标准的类库,提供常用的功能和 API(如 I/O 操作、网络通信、数据结构等)。
简单来说,JRE 只包含运行 Java 程序所需的环境和类库,而 JDK 不仅包含 JRE,还包括用于开发和调试 Java 程序的工具。
如果需要编写、编译 Java 程序或使用 Java API 文档,就需要安装 JDK。某些需要 Java 特性的应用程序(如 JSP 转换为 Servlet 或使用反射)也可能需要 JDK 来编译和运行 Java 代码。因此,即使不进行 Java 开发工作,有时也可能需要安装 JDK。
下图清晰展示了 JDK、JRE 和 JVM 的关系。
不过,从 JDK 9 开始,就不需要区分 JDK 和 JRE 的关系了,取而代之的是模块系统(JDK 被重新组织成 94 个模块)+ jlink 工具 (随 Java 9 一起发布的新命令行工具,用于生成自定义 Java 运行时映像,该映像仅包含给定应用程序所需的模块) 。并且,从 JDK 11 开始,Oracle 不再提供单独的 JRE 下载。
在 Java 9 新特性概览这篇文章中,我在介绍模块化系统的时候提到:
在引入了模块系统之后,JDK 被重新组织成 94 个模块。Java 应用可以通过新增的 jlink 工具,创建出只包含所依赖的 JDK 模块的自定义运行时镜像。这样可以极大的减少 Java 运行时环境的大小。
也就是说,可以用 jlink 根据自己的需求,创建一个更小的 runtime(运行时),而不是不管什么应用,都是同样的 JRE。
定制的、模块化的 Java 运行时映像有助于简化 Java 应用的部署和节省内存并增强安全性和可维护性。这对于满足现代应用程序架构的需求,如虚拟化、容器化、微服务和云原生开发,是非常重要的。
📝 通俗解释
- JDK (Java Development Kit):开发工具包,好比是“厨房”,里面有锅碗瓢盆(编译器、调试器等),专门给厨师(开发者)做饭(写代码)用的。
- JRE (Java Runtime Environment):运行环境,好比是“餐厅”,只有桌椅餐具,专门给客人(用户)吃饭(运行程序)用的。
- JVM (Java Virtual Machine):虚拟机,好比是“大厨”,他负责把做好的饭菜(字节码)根据客人的口味(不同的操作系统)调整一下,让大家都能吃到正宗的味道。
简单说:JDK = JRE + 开发工具;JRE = JVM + 核心类库。我们要开发就装 JDK,只要运行就装 JRE(现在的 JDK 通常都包含了 JRE)。
⭐️什么是字节码?采用字节码的好处是什么?
在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 .class 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以, Java 程序运行时相对来说还是高效的(不过,和 C、 C++,Rust,Go 等语言还是有一定差距的),而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
Java 程序从源代码到运行的过程如下图所示:
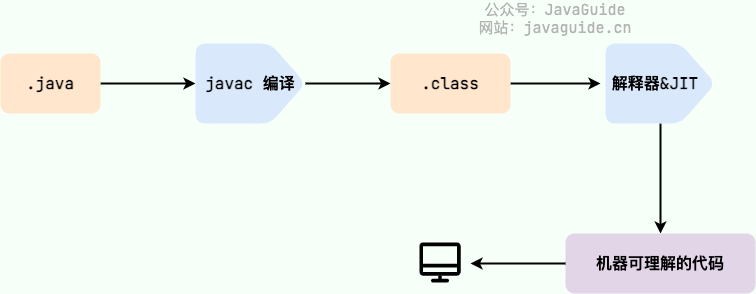
我们需要格外注意的是 .class->机器码 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT(Just in Time Compilation) 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言 。
🌈 拓展阅读:
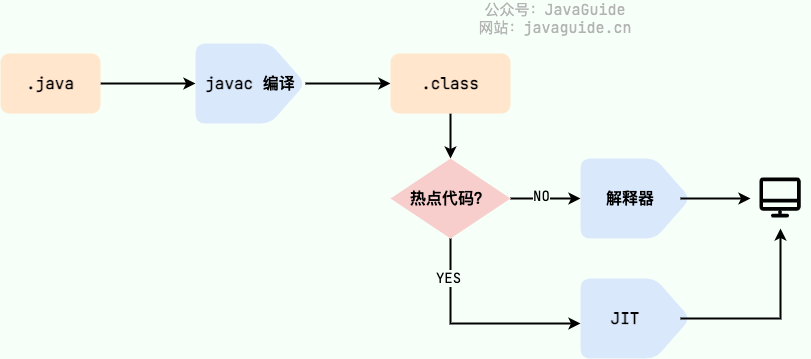
HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。
JDK、JRE、JVM、JIT 这四者的关系如下图所示。
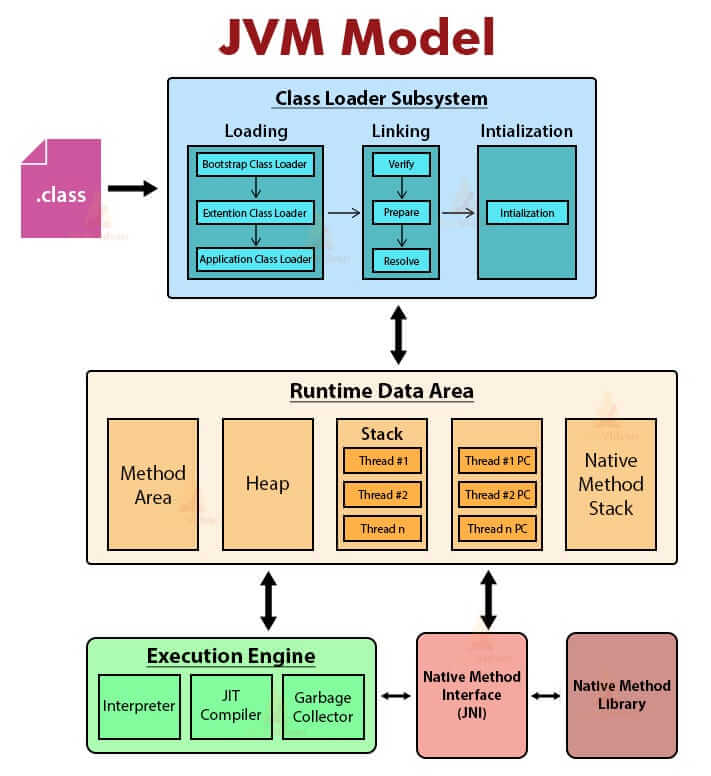
下面这张图是 JVM 的大致结构模型。
📝 通俗解释
字节码(.class 文件)就像是“世界语”乐谱。
传统的编译型语言(如 C++)直接翻译成特定机器的“方言”(机器码),换台机器可能就听不懂了。
Java 先把代码翻译成“世界语乐谱”(字节码),然后由各个地方的 JVM(指挥家)现场把乐谱演奏成当地人听得懂的曲子(机器码)。
好处是:只要有 JVM 这个指挥家,你的乐谱(程序)在任何地方(Windows, Linux, Mac)都能演奏(运行),不用重新写。
⭐️为什么说 Java 语言“编译与解释并存”?
其实这个问题我们讲字节码的时候已经提到过,因为比较重要,所以我们这里再提一下。
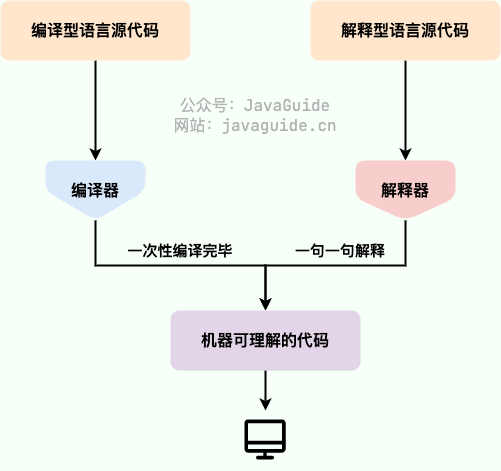
我们可以将高级编程语言按照程序的执行方式分为两种:
- 编译型:编译型语言 会通过编译器将源代码一次性翻译成可被该平台执行的机器码。一般情况下,编译语言的执行速度比较快,开发效率比较低。常见的编译性语言有 C、C++、Go、Rust 等等。
- 解释型:解释型语言会通过解释器一句一句的将代码解释(interpret)为机器代码后再执行。解释型语言开发效率比较快,执行速度比较慢。常见的解释性语言有 Python、JavaScript、PHP 等等。
根据维基百科介绍:
为了改善解释语言的效率而发展出的即时编译技术,已经缩小了这两种语言间的差距。这种技术混合了编译语言与解释型语言的优点,它像编译语言一样,先把程序源代码编译成字节码。到执行期时,再将字节码直译,之后执行。Java与LLVM是这种技术的代表产物。
为什么说 Java 语言“编译与解释并存”?
这是因为 Java 语言既具有编译型语言的特征,也具有解释型语言的特征。因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(.class 文件),这种字节码必须由 Java 解释器来解释执行。
📝 通俗解释
Java 就像是“演讲稿翻译”。
第一步“编译”:先把中文演讲稿(.java)翻译成通用的“世界语”(.class 字节码)。
第二步“解释/执行”:演讲时,现场有一个翻译官(JVM 解释器)一句一句把“世界语”翻译成当地语言给听众听。
为了快一点,翻译官还会把那些经常重复的精彩段落(热点代码)提前背下来(JIT 编译),下次直接背诵,不用再琢磨翻译了。所以 Java 既有编译(生成字节码),又有解释(逐行执行),还有运行时编译(JIT 优化)。
AOT 有什么优点?为什么不全部使用 AOT 呢?
JDK 9 引入了一种新的编译模式 AOT(Ahead of Time Compilation) 。和 JIT 不同的是,这种编译模式会在程序被执行前就将其编译成机器码,属于静态编译(C、 C++,Rust,Go 等语言就是静态编译)。AOT 避免了 JIT 预热等各方面的开销,可以提高 Java 程序的启动速度,避免预热时间长。并且,AOT 还能减少内存占用和增强 Java 程序的安全性(AOT 编译后的代码不容易被反编译和修改),特别适合云原生场景。
JIT 与 AOT 两者的关键指标对比:
| 对比维度 | JIT(即时编译) | AOT(提前编译) |
|---|---|---|
| 编译时机 | 运行时编译 | 运行前编译 |
| 启动速度 | 较慢(需要预热) | 快(无需预热) |
| 峰值性能 | 更高(运行时优化) | 较低(缺少运行时信息) |
| 内存占用 | 较高 | 较低 |
| 打包体积 | 较小 | 较大(包含机器码) |
| 动态特性支持 | 完全支持 | 受限(反射、动态代理等) |
| 适用场景 | 长时间运行的服务 | 云原生、Serverless、CLI 工具 |
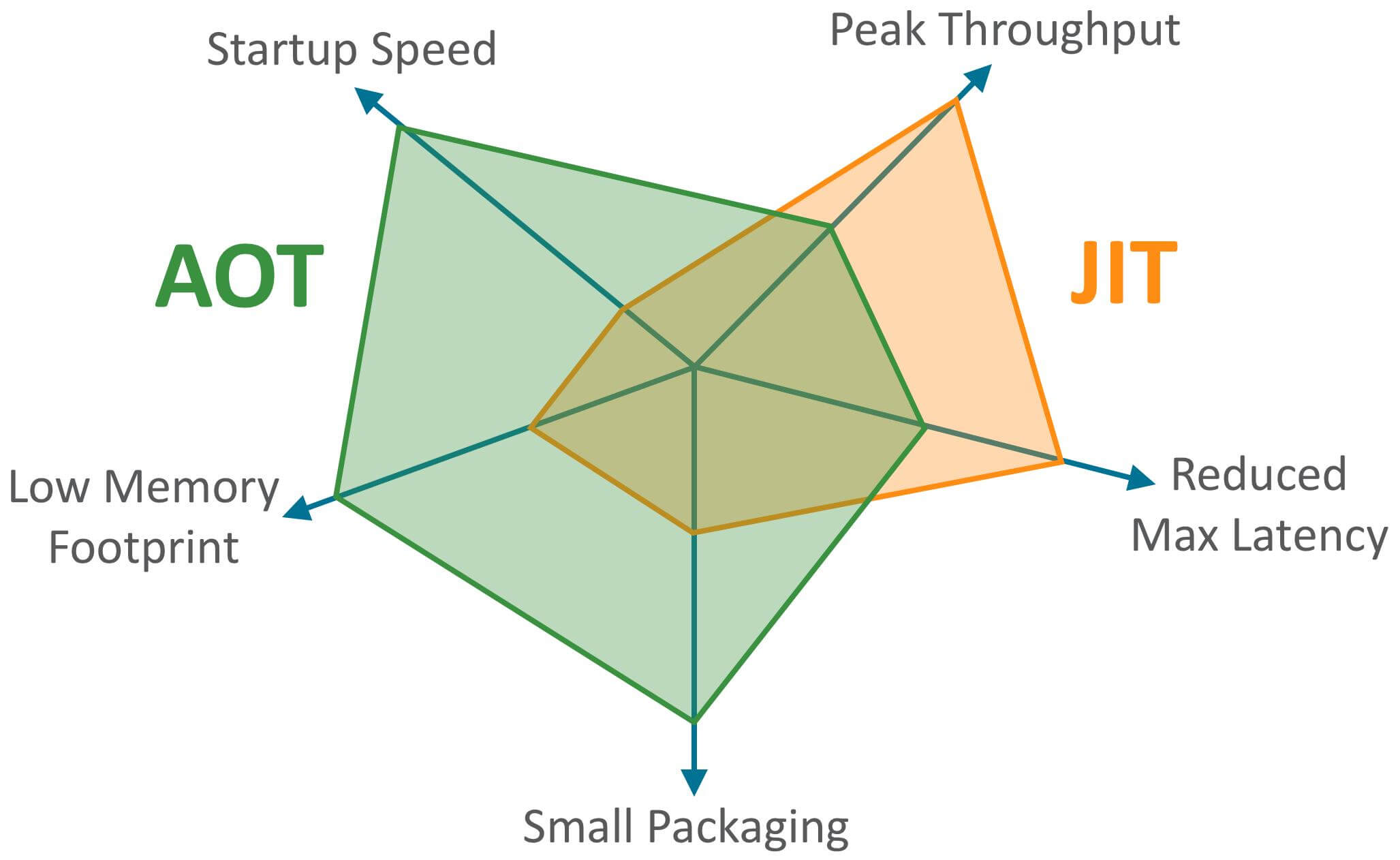
可以看出,AOT 的主要优势在于启动时间、内存占用和打包体积。JIT 的主要优势在于具备更高的极限处理能力,可以降低请求的最大延迟。
提到 AOT 就不得不提 GraalVM 了!GraalVM 是一种高性能的 JDK(完整的 JDK 发行版本),它可以运行 Java 和其他 JVM 语言,以及 JavaScript、Python 等非 JVM 语言。 GraalVM 不仅能提供 AOT 编译,还能提供 JIT 编译。感兴趣的同学,可以去看看 GraalVM 的官方文档:https://www.graalvm.org/latest/docs/。如果觉得官方文档看着比较难理解的话,也可以找一些文章来看看,比如:
既然 AOT 这么多优点,那为什么不全部使用这种编译方式呢?
我们前面也对比过 JIT 与 AOT,两者各有优点,只能说 AOT 更适合当下的云原生场景,对微服务架构的支持也比较友好。除此之外,AOT 编译无法支持 Java 的一些动态特性,如反射、动态代理、动态加载、JNI(Java Native Interface)等。然而,很多框架和库(如 Spring、CGLIB)都用到了这些特性。如果只使用 AOT 编译,那就没办法使用这些框架和库了,或者说需要针对性地去做适配和优化。举个例子,CGLIB 动态代理使用的是 ASM 技术,而这种技术大致原理是运行时直接在内存中生成并加载修改后的字节码文件也就是 .class 文件,如果全部使用 AOT 提前编译,也就不能使用 ASM 技术了。为了支持类似的动态特性,所以选择使用 JIT 即时编译器。
📝 通俗解释
AOT (Ahead of Time) 就像是“提前录播”。节目(程序)在播出前就已经完全录制好(编译成机器码)了,播出时直接放,启动快,不占资源。
JIT (Just in Time) 就像是“现场直播”。节目一边演一边播,虽然开始慢点(预热),但可以根据现场观众反应(运行时信息)即兴发挥(优化),长期看效果可能更好。
为什么不全用 AOT?因为 Java 有些“魔法”(如反射、动态代理)是需要现场发挥的,提前录死(AOT)了就没法变魔术了。而且 JIT 现场优化有时能比提前录好的更高效。
Oracle JDK vs OpenJDK
可能在看这个问题之前很多人和我一样并没有接触和使用过 OpenJDK 。那么 Oracle JDK 和 OpenJDK 之间是否存在重大差异?下面我通过收集到的一些资料,为你解答这个被很多人忽视的问题。
首先,2006 年 SUN 公司将 Java 开源,也就有了 OpenJDK。2009 年 Oracle 收购了 Sun 公司,于是自己在 OpenJDK 的基础上搞了一个 Oracle JDK。Oracle JDK 是不开源的,并且刚开始的几个版本(Java8 ~ Java11)还会相比于 OpenJDK 添加一些特有的功能和工具。
其次,对于 Java 7 而言,OpenJDK 和 Oracle JDK 是十分接近的。 Oracle JDK 是基于 OpenJDK 7 构建的,只添加了一些小功能,由 Oracle 工程师参与维护。
下面这段话摘自 Oracle 官方在 2012 年发表的一个博客:
问:OpenJDK 存储库中的源代码与用于构建 Oracle JDK 的代码之间有什么区别?
答:非常接近 - 我们的 Oracle JDK 版本构建过程基于 OpenJDK 7 构建,只添加了几个部分,例如部署代码,其中包括 Oracle 的 Java 插件和 Java WebStart 的实现,以及一些闭源的第三方组件,如图形光栅化器,一些开源的第三方组件,如 Rhino,以及一些零碎的东西,如附加文档或第三方字体。展望未来,我们的目的是开源 Oracle JDK 的所有部分,除了我们考虑商业功能的部分。
最后,简单总结一下 Oracle JDK 和 OpenJDK 的区别:
- 是否开源:OpenJDK 是一个参考模型并且是完全开源的,而 Oracle JDK 是基于 OpenJDK 实现的,并不是完全开源的(个人观点:众所周知,JDK 原来是 SUN 公司开发的,后来 SUN 公司又卖给了 Oracle 公司,Oracle 公司以 Oracle 数据库而著名,而 Oracle 数据库又是闭源的,这个时候 Oracle 公司就不想完全开源了,但是原来的 SUN 公司又把 JDK 给开源了,如果这个时候 Oracle 收购回来之后就把他给闭源,必然会引起很多 Java 开发者的不满,导致大家对 Java 失去信心,那 Oracle 公司收购回来不就把 Java 烂在手里了吗!然后,Oracle 公司就想了个骚操作,这样吧,我把一部分核心代码开源出来给你们玩,并且我要和你们自己搞的 JDK 区分下,你们叫 OpenJDK,我叫 Oracle JDK,我发布我的,你们继续玩你们的,要是你们搞出来什么好玩的东西,我后续发布 Oracle JDK 也会拿来用一下,一举两得!)OpenJDK 开源项目:https://github.com/openjdk/jdk 。
- 是否免费:Oracle JDK 会提供免费版本,但一般有时间限制。JDK17 之后的版本可以免费分发和商用,但是仅有 3 年时间,3 年后无法免费商用。不过,JDK8u221 之前只要不升级可以无限期免费。OpenJDK 是完全免费的。
- 功能性:Oracle JDK 在 OpenJDK 的基础上添加了一些特有的功能和工具,比如 Java Flight Recorder(JFR,一种监控工具)、Java Mission Control(JMC,一种监控工具)等工具。不过,在 Java 11 之后,OracleJDK 和 OpenJDK 的功能基本一致,之前 OracleJDK 中的私有组件大多数也已经被捐赠给开源组织。
- 稳定性:OpenJDK 不提供 LTS 服务,而 OracleJDK 大概每三年都会推出一个 LTS 版进行长期支持。不过,很多公司都基于 OpenJDK 提供了对应的和 OracleJDK 周期相同的 LTS 版。因此,两者稳定性其实也是差不多的。
- 协议:Oracle JDK 使用 BCL/OTN 协议获得许可,而 OpenJDK 根据 GPL v2 许可获得许可。
既然 Oracle JDK 这么好,那为什么还要有 OpenJDK?
答:
- OpenJDK 是开源的,开源意味着你可以对它根据你自己的需要进行修改、优化,比如 Alibaba 基于 OpenJDK 开发了 Dragonwell8:https://github.com/alibaba/dragonwell8
- OpenJDK 是商业免费的(这也是为什么通过 yum 包管理器上默认安装的 JDK 是 OpenJDK 而不是 Oracle JDK)。虽然 Oracle JDK 也是商业免费(比如 JDK 8),但并不是所有版本都是免费的。
- OpenJDK 更新频率更快。Oracle JDK 一般是每 6 个月发布一个新版本,而 OpenJDK 一般是每 3 个月发布一个新版本。(现在你知道为啥 Oracle JDK 更稳定了吧,先在 OpenJDK 试试水,把大部分问题都解决掉了才在 Oracle JDK 上发布)
基于以上这些原因,OpenJDK 还是有存在的必要的!
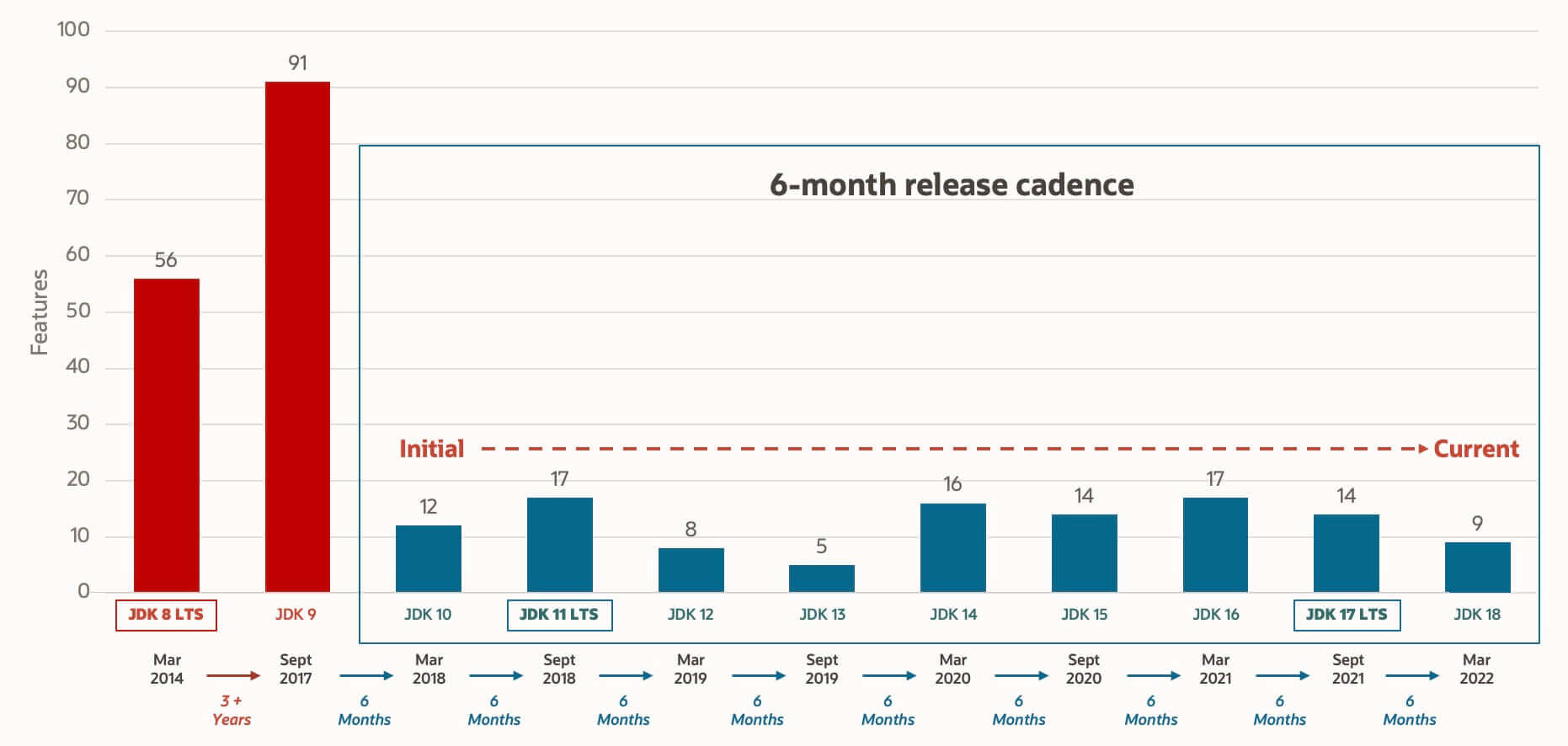
Oracle JDK 和 OpenJDK 如何选择?
建议选择 OpenJDK 或者基于 OpenJDK 的发行版,比如 AWS 的 Amazon Corretto,阿里巴巴的 Alibaba Dragonwell。
🌈 拓展一下:
- BCL 协议(Oracle Binary Code License Agreement):可以使用 JDK(支持商用),但是不能进行修改。
- OTN 协议(Oracle Technology Network License Agreement):11 及之后新发布的 JDK 用的都是这个协议,可以自己私下用,但是商用需要付费。
📝 通俗解释
OpenJDK 是“开源社区版”,就像安卓系统的原生代码,免费、开源,谁都能拿去改。
Oracle JDK 是“官方商业版”,就像谷歌亲儿子 Pixel 手机的系统,基于开源版加了一些官方的专属服务、优化和商业支持。
现在的版本(Java 11+)两者核心代码几乎一样,普通人用起来没区别。就像两瓶水,一瓶贴了“官方特供”标签,一瓶是“惠民通用”标签,喝起来味道差不多。
Java 和 C++ 的区别?
我知道很多人没学过 C++,但是“学习”官就是没事喜欢拿咱们 Java 和 C++ 比呀!没办法!!!就算没学过 C++,也要记下来。
虽然,Java 和 C++ 都是面向对象的语言,都支持封装、继承和多态,但是,它们还是有挺多不相同的地方:
- Java 不提供指针来直接访问内存,程序内存更加安全
- Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。
- Java 有自动内存管理垃圾回收机制(GC),不需要程序员手动释放无用内存。
- C ++同时支持方法重载和操作符重载,但是 Java 只支持方法重载(操作符重载增加了复杂性,这与 Java 最初的设计思想不符)。
- ……
📝 通俗解释
Java 是“简化版”且“安全版”的 C++。
- 不直接玩内存:C++ 可以直接操作内存地址(指针),容易玩脱(内存泄漏、崩溃);Java 把指针藏起来了,内存由系统自动管理(GC),更安全。
- 单继承:C++ 一个儿子可以有多个爸爸(多继承),容易乱;Java 一个儿子只能有一个亲爸爸(单继承),但可以认很多干爹(接口)。
- 跨平台:Java 编译成字节码,随便在哪跑;C++ 编译成机器码,换个系统得重编。
基本语法
注释有哪几种形式?
Java 中的注释有三种:
单行注释:通常用于解释方法内某单行代码的作用。
多行注释:通常用于解释一段代码的作用。
文档注释:通常用于生成 Java 开发文档。
用的比较多的还是单行注释和文档注释,多行注释在实际开发中使用的相对较少。
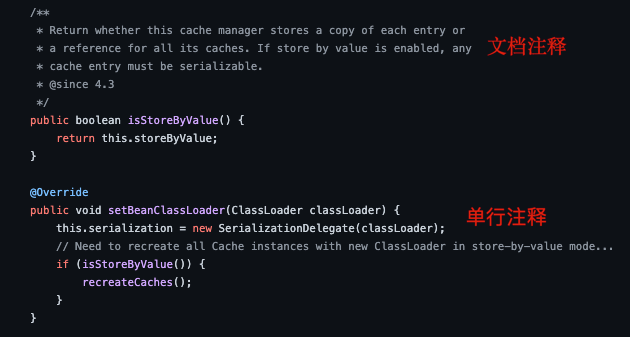
在我们编写代码的时候,如果代码量比较少,我们自己或者团队其他成员还可以很轻易地看懂代码,但是当项目结构一旦复杂起来,我们就需要用到注释了。注释并不会执行(编译器在编译代码之前会把代码中的所有注释抹掉,字节码中不保留注释),是我们程序员写给自己看的,注释是你的代码说明书,能够帮助看代码的人快速地理清代码之间的逻辑关系。因此,在写程序的时候随手加上注释是一个非常好的习惯。
《Clean Code》这本书明确指出:
代码的注释不是越详细越好。实际上好的代码本身就是注释,我们要尽量规范和美化自己的代码来减少不必要的注释。
若编程语言足够有表达力,就不需要注释,尽量通过代码来阐述。
举个例子:
去掉下面复杂的注释,只需要创建一个与注释所言同一事物的函数即可
// check to see if the employee is eligible for full benefits if ((employee.flags & HOURLY_FLAG) && (employee.age > 65))应替换为
if (employee.isEligibleForFullBenefits())
📝 通俗解释
注释就是代码的“说明书”。
- 单行注释 (//):像是便利贴,随手写在某行代码旁边,解释这一行干啥。
- 多行注释 (/_ ... _/):像是段落说明,解释一大段代码的功能。
- 文档注释 (/ ... */)**:像是正式的产品手册,可以自动生成网页版的说明书(Javadoc),给别人看你写的库怎么用。
标识符和关键字的区别是什么?
在我们编写程序的时候,需要大量地为程序、类、变量、方法等取名字,于是就有了 标识符 。简单来说, 标识符就是一个名字 。
有一些标识符,Java 语言已经赋予了其特殊的含义,只能用于特定的地方,这些特殊的标识符就是 关键字 。简单来说,关键字是被赋予特殊含义的标识符 。比如,在我们的日常生活中,如果我们想要开一家店,则要给这个店起一个名字,起的这个“名字”就叫标识符。但是我们店的名字不能叫“警察局”,因为“警察局”这个名字已经被赋予了特殊的含义,而“警察局”就是我们日常生活中的关键字。
📝 通俗解释
- 标识符:是你给变量、类、方法起的“名字”(如
myCar,User)。- 关键字:是 Java 语言自己保留的“专用词”(如
class,public,if)。就像你给孩子起名(标识符),不能起名叫“警察”或“医生”(关键字),因为这些词在社会中有特殊含义。
Java 语言关键字有哪些?
| 分类 | 关键字 | ||||||
|---|---|---|---|---|---|---|---|
| 访问控制 | private | protected | public | ||||
| 类,方法和变量修饰符 | abstract | class | extends | final | implements | interface | native |
| new | static | strictfp | synchronized | transient | volatile | enum | |
| 程序控制 | break | continue | return | do | while | if | else |
| for | instanceof | switch | case | default | assert | ||
| 错误处理 | try | catch | throw | throws | finally | ||
| 包相关 | import | package | |||||
| 基本类型 | boolean | byte | char | double | float | int | long |
| short | |||||||
| 变量引用 | super | this | void | ||||
| 保留字 | goto | const |
Tips:所有的关键字都是小写的,在 IDE 中会以特殊颜色显示。
default这个关键字很特殊,既属于程序控制,也属于类,方法和变量修饰符,还属于访问控制。
- 在程序控制中,当在
switch中匹配不到任何情况时,可以使用default来编写默认匹配的情况。- 在类,方法和变量修饰符中,从 JDK8 开始引入了默认方法,可以使用
default关键字来定义一个方法的默认实现。- 在访问控制中,如果一个方法前没有任何修饰符,则默认会有一个修饰符
default,但是这个修饰符加上了就会报错。
⚠️ 注意:虽然 true, false, 和 null 看起来像关键字但实际上他们是字面值,同时你也不可以作为标识符来使用。
官方文档:https://docs.oracle.com/javase/tutorial/java/nutsandbolts/_keywords.html
📝 通俗解释
这里列出了 Java 的“专用词汇表”。这些词你不能拿来做名字(变量名、类名)。
比如private(私有的)、class(类)、if(如果)、return(返回)。
注意:true,false,null虽然不是关键字,但也是“保留字”,也不能当名字用。
⭐️自增自减运算符
在写代码的过程中,常见的一种情况是需要某个整数类型变量增加 1 或减少 1。Java 提供了自增运算符 (++) 和自减运算符 (--) 来简化这种操作。
++ 和 -- 运算符可以放在变量之前,也可以放在变量之后:
- 前缀形式(例如
++a或--a):先自增/自减变量的值,然后再使用该变量,例如,b = ++a先将a增加 1,然后把增加后的值赋给b。 - 后缀形式(例如
a++或a--):先使用变量的当前值,然后再自增/自减变量的值。例如,b = a++先将a的当前值赋给b,然后再将a增加 1。
为了方便记忆,可以使用下面的口诀:符号在前就先加/减,符号在后就后加/减。
下面来看一个考察自增自减运算符的高频笔试题:执行下面的代码后,a 、b 、 c 、d和e的值是?
int a = 9;
int b = a++;
int c = ++a;
int d = c--;
int e = --d;答案:a = 11 、b = 9 、 c = 10 、 d = 10 、 e = 10。
📝 通俗解释
++就是“给自己加 1”,--就是“给自己减 1”。
++i(先加后用):像“先买票后上车”。变量自己先加 1,然后再拿去用。i++(先用后加):像“先上车后补票”。先把变量现在的值拿去用,用完后变量自己再加 1。比如
a=1。b = ++a->a变 2,b得到 2。b = a++->b得到 1,a变 2。
⭐️移位运算符
移位运算符是最基本的运算符之一,几乎每种编程语言都包含这一运算符。移位操作中,被操作的数据被视为二进制数,移位就是将其向左或向右移动若干位的运算。
移位运算符在各种框架以及 JDK 自身的源码中使用还是挺广泛的,HashMap(JDK1.8) 中的 hash 方法的源码就用到了移位运算符:
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^:按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}使用移位运算符的主要原因:
- 高效:移位运算符直接对应于处理器的移位指令。现代处理器具有专门的硬件指令来执行这些移位操作,这些指令通常在一个时钟周期内完成。相比之下,乘法和除法等算术运算在硬件层面上需要更多的时钟周期来完成。
- 节省内存:通过移位操作,可以使用一个整数(如
int或long)来存储多个布尔值或标志位,从而节省内存。
移位运算符最常用于快速乘以或除以 2 的幂次方。除此之外,它还在以下方面发挥着重要作用:
- 位字段管理:例如存储和操作多个布尔值。
- 哈希算法和加密解密:通过移位和与、或等操作来混淆数据。
- 数据压缩:例如霍夫曼编码通过移位运算符可以快速处理和操作二进制数据,以生成紧凑的压缩格式。
- 数据校验:例如 CRC(循环冗余校验)通过移位和多项式除法生成和校验数据完整性。
- 内存对齐:通过移位操作,可以轻松计算和调整数据的对齐地址。
掌握最基本的移位运算符知识还是很有必要的,这不光可以帮助我们在代码中使用,还可以帮助我们理解源码中涉及到移位运算符的代码。
Java 中有三种移位运算符:
<<:左移运算符,向左移若干位,高位丢弃,低位补零。x << n,相当于 x 乘以 2 的 n 次方(不溢出的情况下)。>>:带符号右移,向右移若干位,高位补符号位,低位丢弃。正数高位补 0,负数高位补 1。x >> n,相当于 x 除以 2 的 n 次方。>>>:无符号右移,忽略符号位,空位都以 0 补齐。
虽然移位运算本质上可以分为左移和右移,但在实际应用中,右移操作需要考虑符号位的处理方式。
由于 double,float 在二进制中的表现比较特殊,因此不能来进行移位操作。
移位操作符实际上支持的类型只有int和long,编译器在对short、byte、char类型进行移位前,都会将其转换为int类型再操作。
如果移位的位数超过数值所占有的位数会怎样?
当 int 类型左移/右移位数大于等于 32 位操作时,会先求余(%)后再进行左移/右移操作。也就是说左移/右移 32 位相当于不进行移位操作(32%32=0),左移/右移 42 位相当于左移/右移 10 位(42%32=10)。当 long 类型进行左移/右移操作时,由于 long 对应的二进制是 64 位,因此求余操作的基数也变成了 64。
也就是说:x<<42等同于x<<10,x>>42等同于x>>10,x >>>42等同于x >>> 10。
左移运算符代码示例:
int i = -1;
System.out.println("初始数据:" + i);
System.out.println("初始数据对应的二进制字符串:" + Integer.toBinaryString(i));
i <<= 10;
System.out.println("左移 10 位后的数据 " + i);
System.out.println("左移 10 位后的数据对应的二进制字符 " + Integer.toBinaryString(i));输出:
初始数据:-1
初始数据对应的二进制字符串:11111111111111111111111111111111
左移 10 位后的数据 -1024
左移 10 位后的数据对应的二进制字符 11111111111111111111110000000000由于左移位数大于等于 32 位操作时,会先求余(%)后再进行左移操作,所以下面的代码左移 42 位相当于左移 10 位(42%32=10),输出结果和前面的代码一样。
int i = -1;
System.out.println("初始数据:" + i);
System.out.println("初始数据对应的二进制字符串:" + Integer.toBinaryString(i));
i <<= 42;
System.out.println("左移 10 位后的数据 " + i);
System.out.println("左移 10 位后的数据对应的二进制字符 " + Integer.toBinaryString(i));右移运算符使用类似,篇幅问题,这里就不做演示了。
📝 通俗解释
移位就是把数字的二进制位像算盘珠子一样左右拨动。
- 左移
<<:所有位向左跑,右边补 0。每移 1 位相当于 乘 2。- 右移 >>:所有位向右跑。每移 1 位相当于 除 2。
- 无符号右移 >>>:不管正负,高位统统补 0(通常用来处理逻辑位运算,不涉及数学计算)。
移位运算比直接做乘除法快得多,是计算机底层的“心算”技巧。
continue、break 和 return 的区别是什么?
在循环结构中,当循环条件不满足或者循环次数达到要求时,循环会正常结束。但是,有时候可能需要在循环的过程中,当发生了某种条件之后 ,提前终止循环,这就需要用到下面几个关键词:
continue:指跳出当前的这一次循环,继续下一次循环。break:指跳出整个循环体,继续执行循环下面的语句。
return 用于跳出所在方法,结束该方法的运行。return 一般有两种用法:
return;:直接使用 return 结束方法执行,用于没有返回值函数的方法return value;:return 一个特定值,用于有返回值函数的方法
思考一下:下列语句的运行结果是什么?
public static void main(String[] args) {
boolean flag = false;
for (int i = 0; i <= 3; i++) {
if (i == 0) {
System.out.println("0");
} else if (i == 1) {
System.out.println("1");
continue;
} else if (i == 2) {
System.out.println("2");
flag = true;
} else if (i == 3) {
System.out.println("3");
break;
} else if (i == 4) {
System.out.println("4");
}
System.out.println("xixi");
}
if (flag) {
System.out.println("haha");
return;
}
System.out.println("heihei");
}运行结果:
0
xixi
1
2
xixi
3
haha📝 通俗解释
都在循环(跑步)中使用:
continue:这圈不跑了,直接跳到起跑线开始 下一圈。break:这比赛不跑了,直接 退赛,去干别的事(执行循环后面的代码)。return:整个人 回家 了,不仅比赛结束,连所在的这个方法(函数)也彻底结束。
⭐️基本数据类型
Java 中的几种基本数据类型了解么?
Java 中有 8 种基本数据类型,分别为:
- 6 种数字类型:
- 4 种整数型:
byte、short、int、long - 2 种浮点型:
float、double
- 4 种整数型:
- 1 种字符类型:
char - 1 种布尔型:
boolean。
这 8 种基本数据类型的默认值以及所占空间的大小如下:
| 基本类型 | 位数 | 字节 | 默认值 | 取值范围 |
|---|---|---|---|---|
byte | 8 | 1 | 0 | -128 ~ 127 |
short | 16 | 2 | 0 | -32768(-2^15) ~ 32767(2^15 - 1) |
int | 32 | 4 | 0 | -2147483648 ~ 2147483647 |
long | 64 | 8 | 0L | -9223372036854775808(-2^63) ~ 9223372036854775807(2^63 -1) |
char | 16 | 2 | 'u0000' | 0 ~ 65535(2^16 - 1) |
float | 32 | 4 | 0f | 1.4E-45 ~ 3.4028235E38 |
double | 64 | 8 | 0d | 4.9E-324 ~ 1.7976931348623157E308 |
boolean | 1 | false | true、false |
可以看到,像 byte、short、int、long能表示的最大正数都减 1 了。这是为什么呢?这是因为在二进制补码表示法中,最高位是用来表示符号的(0 表示正数,1 表示负数),其余位表示数值部分。所以,如果我们要表示最大的正数,我们需要把除了最高位之外的所有位都设为 1。如果我们再加 1,就会导致溢出,变成一个负数。
对于 boolean,官方文档未明确定义,它依赖于 JVM 厂商的具体实现。逻辑上理解是占用 1 位,但是实际中会考虑计算机高效存储因素。
另外,Java 的每种基本类型所占存储空间的大小不会像其他大多数语言那样随机器硬件架构的变化而变化。这种所占存储空间大小的不变性是 Java 程序比用其他大多数语言编写的程序更具可移植性的原因之一(《Java 编程思想》2.2 节有提到)。
注意:
- Java 里使用
long类型的数据一定要在数值后面加上 L,否则将作为整型解析。 - Java 里使用
float类型的数据一定要在数值后面加上 f 或 F,否则将无法通过编译。 char a = 'h'char :单引号,String a = "hello":双引号。
这八种基本类型都有对应的包装类分别为:Byte、Short、Integer、Long、Float、Double、Character、Boolean 。
📝 通俗解释
Java 有 8 种最基本的“积木块”,用来搭建所有数据:
- 整数类:
byte(1字节, 极短),short(2字节, 短),int(4字节, 标准),long(8字节, 超长)。- 小数类:
float(单精度, 不太准),double(双精度, 准一点)。- 文字类:
char(存一个字, 如 'A')。- 判断类:
boolean(真 true / 假 false)。除了这 8 种,其他的(如 String, 数组, 自定义类)全都是“引用类型”(对象)。
基本类型和包装类型的区别?
- 用途:除了定义一些常量和局部变量之外,我们在其他地方比如方法参数、对象属性中很少会使用基本类型来定义变量。并且,包装类型可用于泛型,而基本类型不可以。
- 存储方式:基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被
static修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。 - 占用空间:相比于包装类型(对象类型), 基本数据类型占用的空间往往非常小。
- 默认值:成员变量包装类型不赋值就是
null,而基本类型有默认值且不是null。 - 比较方式:对于基本数据类型来说,
==比较的是值。对于包装数据类型来说,==比较的是对象的内存地址。所有整型包装类对象之间值的比较,全部使用equals()方法。
为什么说是几乎所有对象实例都存在于堆中呢? 这是因为 HotSpot 虚拟机引入了 JIT 优化之后,会对对象进行逃逸分析,如果发现某一个对象并没有逃逸到方法外部,那么就可能通过标量替换来实现栈上分配,而避免堆上分配内存
⚠️ 注意:基本数据类型存放在栈中是一个常见的误区! 基本数据类型的存储位置取决于它们的作用域和声明方式。如果它们是局部变量,那么它们会存放在栈中;如果它们是成员变量,那么它们会存放在堆/方法区/元空间中。
public class Test {
// 成员变量,存放在堆中
int a = 10;
// 被 static 修饰的成员变量,JDK 1.7 及之前位于方法区,1.8 后存放于元空间,均不存放于堆中。
// 变量属于类,不属于对象。
static int b = 20;
public void method() {
// 局部变量,存放在栈中
int c = 30;
static int d = 40; // 编译错误,不能在方法中使用 static 修饰局部变量
}
}📝 通俗解释
- 基本类型 (int, double...):是“素颜”,数据直接存在栈里,轻量、快,但功能少(不能 null,不能调方法)。
- 包装类型 (Integer, Double...):是“化妆后”的对象,把基本数据包了一层皮,存在堆里。虽然重一点,但功能多(可以为 null,可以用于泛型
List<Integer>)。就像“散装糖果”和“精美礼盒装糖果”。平时自己吃(计算)用散装的(基本类型)省钱;送人(存入集合、泛型)得用礼盒装的(包装类型)。
包装类型的缓存机制了解么?
Java 基本数据类型的包装类型的大部分都用到了缓存机制来提升性能。
Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回 TRUE or FALSE。
对于 Integer,可以通过 JVM 参数 -XX:AutoBoxCacheMax=<size> 修改缓存上限,但不能修改下限 -128。实际使用时,并不建议设置过大的值,避免浪费内存,甚至是 OOM。
对于Byte,Short,Long ,Character 没有类似 -XX:AutoBoxCacheMax 参数可以修改,因此缓存范围是固定的,无法通过 JVM 参数调整。Boolean 则直接返回预定义的 TRUE 和 FALSE 实例,没有缓存范围的概念。
Integer 缓存源码:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static {
// high value may be configured by property
int h = 127;
}
}Character 缓存源码:
public static Character valueOf(char c) {
if (c <= 127) { // must cache
return CharacterCache.cache[(int)c];
}
return new Character(c);
}
private static class CharacterCache {
private CharacterCache(){}
static final Character cache[] = new Character[127 + 1];
static {
for (int i = 0; i < cache.length; i++)
cache[i] = new Character((char)i);
}
}Boolean 缓存源码:
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}如果超出对应范围仍然会去创建新的对象,缓存的范围区间的大小只是在性能和资源之间的权衡。
两种浮点数类型的包装类 Float,Double 并没有实现缓存机制。
Integer i1 = 33;
Integer i2 = 33;
System.out.println(i1 == i2);// 输出 true
Float i11 = 333f;
Float i22 = 333f;
System.out.println(i11 == i22);// 输出 false
Double i3 = 1.2;
Double i4 = 1.2;
System.out.println(i3 == i4);// 输出 false下面我们来看一个问题:下面的代码的输出结果是 true 还是 false 呢?
Integer i1 = 40;
Integer i2 = new Integer(40);
System.out.println(i1==i2);Integer i1=40 这一行代码会发生装箱,也就是说这行代码等价于 Integer i1=Integer.valueOf(40) 。因此,i1 直接使用的是缓存中的对象。而Integer i2 = new Integer(40) 会直接创建新的对象。
因此,答案是 false 。你答对了吗?
记住:所有整型包装类对象之间值的比较,全部使用 equals 方法比较。

📝 通俗解释
Java 为了省内存,把常用的数字(-128 到 127)提前造好放在“仓库”(缓存池)里了。
当你用Integer i = 100时,它直接从仓库拿给你,大家拿到的都是同一个对象。
当你用Integer i = 200(超出了缓存范围)时,它才会现场造一个新的对象给你。
所以,比较两个 Integer 对象时,小数(缓存范围内)可能相等,大数(缓存范围外)就不相等了。为了不出错,对象比较一定要用.equals()!
自动装箱与拆箱了解吗?原理是什么?
什么是自动拆装箱?
- 装箱(Boxing):将基本类型用它们对应的引用类型包装起来;
- 拆箱(Unboxing):将包装类型转换为基本数据类型;
举例:
Integer i = 10; //装箱
int n = i; //拆箱上面这两行代码对应的字节码为:
L1
LINENUMBER 8 L1
ALOAD 0
BIPUSH 10
INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer;
PUTFIELD AutoBoxTest.i : Ljava/lang/Integer;
L2
LINENUMBER 9 L2
ALOAD 0
ALOAD 0
GETFIELD AutoBoxTest.i : Ljava/lang/Integer;
INVOKEVIRTUAL java/lang/Integer.intValue ()I
PUTFIELD AutoBoxTest.n : I
RETURN从字节码中,我们发现装箱其实就是调用了 包装类的valueOf()方法,拆箱其实就是调用了 xxxValue()方法。
因此,
Integer i = 10等价于Integer i = Integer.valueOf(10)int n = i等价于int n = i.intValue();
注意:如果频繁拆装箱的话,也会严重影响系统的性能。我们应该尽量避免不必要的拆装箱操作。
private static long sum() {
// 应该使用 long 而不是 Long
Long sum = 0L;
for (long i = 0; i <= Integer.MAX_VALUE; i++)
sum += i;
return sum;
}📝 通俗解释
Java 编译器很贴心,会自动帮你在“基本类型”和“包装类型”之间转换。
- 装箱:
int->Integer。就像把散糖果装进礼盒。原理是自动调用Integer.valueOf()。- 拆箱:
Integer->int。就像把礼盒拆开拿出糖果。原理是自动调用intValue()。这样你写代码时就不用手动转来转去了,但要注意频繁拆装箱会降低性能。
为什么浮点数运算的时候会有精度丢失的风险?
浮点数运算精度丢失代码演示:
float a = 2.0f - 1.9f;
float b = 1.8f - 1.7f;
System.out.printf("%.9f",a);// 0.100000024
System.out.println(b);// 0.099999905
System.out.println(a == b);// false为什么会出现这个问题呢?
这个和计算机保存浮点数的机制有很大关系。我们知道计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。这也就解释了为什么浮点数没有办法用二进制精确表示。
就比如说十进制下的 0.2 就没办法精确转换成二进制小数:
// 0.2 转换为二进制数的过程为,不断乘以 2,直到不存在小数为止,
// 在这个计算过程中,得到的整数部分从上到下排列就是二进制的结果。
0.2 * 2 = 0.4 -> 0
0.4 * 2 = 0.8 -> 0
0.8 * 2 = 1.6 -> 1
0.6 * 2 = 1.2 -> 1
0.2 * 2 = 0.4 -> 0(发生循环)
...关于浮点数的更多内容,建议看一下计算机系统基础(四)浮点数这篇文章。
📝 通俗解释
因为计算机只能存 0 和 1。有些十进制小数(比如 0.2)换算成二进制是无限循环小数(0.00110011...)。
但计算机内存有限,存不下无限长,只能截断。这一截断,精度就丢了。
就像用 3 位小数表示 1/3 (0.333),结果肯定是不准的。
所以,千万别用 float/double 算钱!
如何解决浮点数运算的精度丢失问题?
BigDecimal 可以实现对浮点数的运算,不会造成精度丢失。通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 BigDecimal 来做的。
BigDecimal a = new BigDecimal("1.0");
BigDecimal b = new BigDecimal("1.00");
BigDecimal c = new BigDecimal("0.8");
BigDecimal x = a.subtract(c);
BigDecimal y = b.subtract(c);
System.out.println(x); /* 0.2 */
System.out.println(y); /* 0.20 */
// 比较内容,不是比较值
System.out.println(Objects.equals(x, y)); /* false */
// 比较值相等用相等compareTo,相等返回0
System.out.println(0 == x.compareTo(y)); /* true */关于 BigDecimal 的详细介绍,可以看看我写的这篇文章:BigDecimal 详解。
📝 通俗解释
既然 float/double 算不准,Java 提供了一个专业的数学工具类:BigDecimal。
它就像“高精度计算器”,能精确处理任意位数的小数。
算钱的时候,一定要用BigDecimal,而且创建它的时候最好用 字符串 构造函数new BigDecimal("0.1"),不然还是可能会丢精度。
超过 long 整型的数据应该如何表示?
基本数值类型都有一个表达范围,如果超过这个范围就会有数值溢出的风险。
在 Java 中,64 位 long 整型是最大的整数类型。
long l = Long.MAX_VALUE;
System.out.println(l + 1); // -9223372036854775808
System.out.println(l + 1 == Long.MIN_VALUE); // trueBigInteger 内部使用 int[] 数组来存储任意大小的整形数据。
相对于常规整数类型的运算来说,BigInteger 运算的效率会相对较低。
📝 通俗解释
long再大也有上限(约 19 位数字)。如果还要更大(比如天文数字、加密算法),就用BigInteger。
它理论上可以存无限大的整数(只受内存限制),但也因为是对象操作,运算速度比基本类型慢得多。
变量
⭐️成员变量与局部变量的区别?
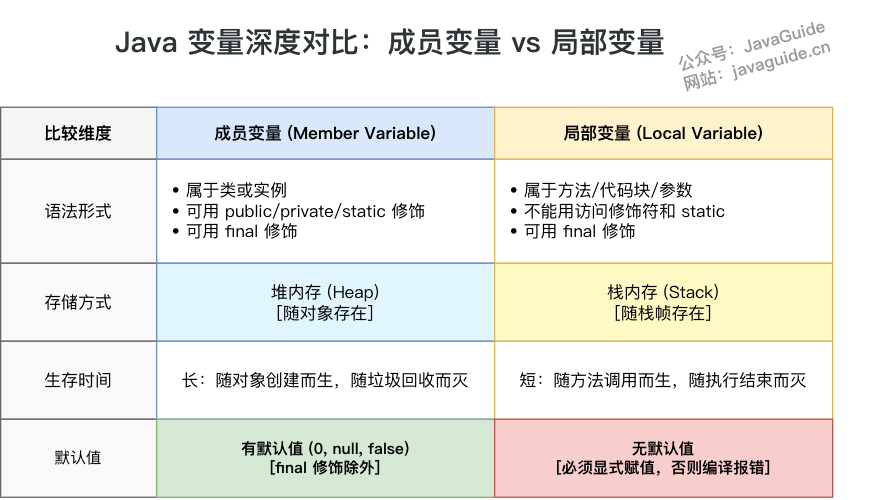
- 语法形式:从语法形式上看,成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被
public,private,static等修饰符所修饰,而局部变量不能被访问控制修饰符及static所修饰;但是,成员变量和局部变量都能被final所修饰。 - 存储方式:从变量在内存中的存储方式来看,如果成员变量是使用
static修饰的,那么这个成员变量是属于类的,如果没有使用static修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。 - 生存时间:从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动生成,随着方法的调用结束而消亡。
- 默认值:从变量是否有默认值来看,成员变量如果没有被赋初始值,则会自动以类型的默认值而赋值(一种情况例外:被
final修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
为什么成员变量有默认值?
核心原因是为了保证对象状态的安全和可预测性。
成员变量和局部变量在这个规则上不同,主要是因为它们的生命周期不一样,导致了编译器对它们的“控制力”也不同。
- 局部变量只活在一个方法里,编译器能清楚地看到它是否在使用前被赋值,所以编译器会强制你必须手动赋值,否则就报错。
- 成员变量是跟着对象走的,它的值可能在构造函数里赋,也可能在后面的某个
setter方法里赋。编译器在编译时无法预测它到底什么时候会被赋值。
并且,如果一个变量没有被初始化,它的内存里存放的就是“垃圾值”——之前那块内存遗留下的任意数据。如果程序读取并使用了这个垃圾值,就会产生完全不可预测的结果,比如一个数字变成了随机数,一个对象引用变成了非法地址,这会直接导致程序崩溃或出现诡异的 bug。
为了避免你拿到一个含有“垃圾值”的危险对象,Java干脆为所有成员变量提供了一个安全的默认值(如 null 或 0),作为一种安全兜底机制。
成员变量与局部变量代码示例:
public class VariableExample {
// 成员变量
private String name;
private int age;
// 方法中的局部变量
public void method() {
int num1 = 10; // 栈中分配的局部变量
String str = "Hello, world!"; // 栈中分配的局部变量
System.out.println(num1);
System.out.println(str);
}
// 带参数的方法中的局部变量
public void method2(int num2) {
int sum = num2 + 10; // 栈中分配的局部变量
System.out.println(sum);
}
// 构造方法中的局部变量
public VariableExample(String name, int age) {
this.name = name; // 对成员变量进行赋值
this.age = age; // 对成员变量进行赋值
int num3 = 20; // 栈中分配的局部变量
String str2 = "Hello, " + this.name + "!"; // 栈中分配的局部变量
System.out.println(num3);
System.out.println(str2);
}
}📝 通俗解释
- 成员变量:属于“家”(对象)的,比如你的名字、年龄。一直存在,直到家(对象)没了。有默认值(比如 int 默认 0)。
- 局部变量:属于“临时任务”(方法)的,比如做饭时用的临时变量。任务做完就扔了。没有默认值,不赋值不能用!
最大的坑:局部变量必须手动初始化,不然编译器会报错。
静态变量有什么作用?
静态变量也就是被 static 关键字修饰的变量。它可以被类的所有实例共享,无论一个类创建了多少个对象,它们都共享同一份静态变量。也就是说,静态变量只会被分配一次内存,即使创建多个对象,这样可以节省内存。
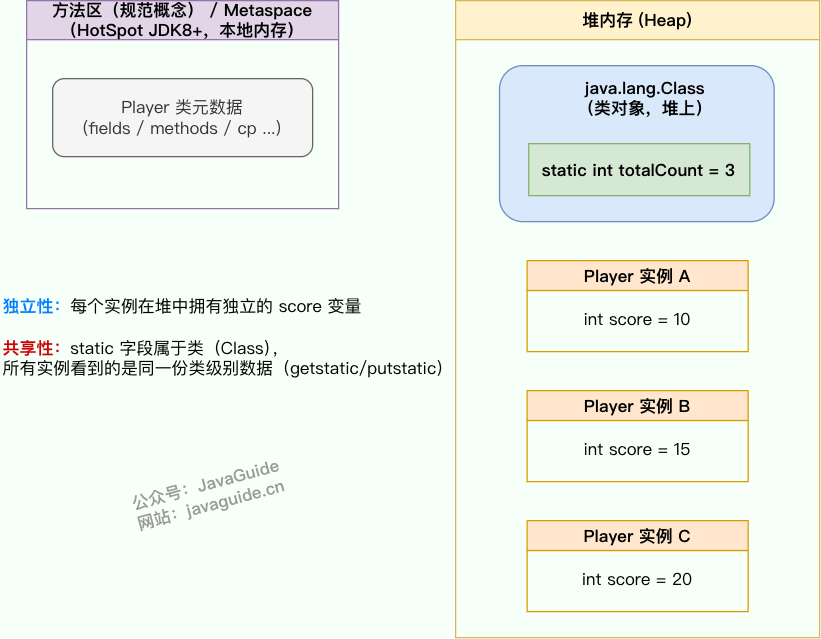
静态变量是通过类名来访问的,例如StaticVariableExample.staticVar(如果被 private关键字修饰就无法这样访问了)。
public class StaticVariableExample {
// 静态变量
public static int staticVar = 0;
}通常情况下,静态变量会被 final 关键字修饰成为常量。
public class ConstantVariableExample {
// 常量
public static final int constantVar = 0;
}📝 通俗解释
静态变量(static)是属于 “全班共有” 的,不是属于“某个人”的。
比如“班费”,不管班里有多少学生(对象),班费只有一份,大家共用。
只要改了它,所有人看到的都变了。通常用来存常量(如PI)或全局配置。
字符型常量和字符串常量的区别?
- 形式 : 字符常量是单引号引起的一个字符,字符串常量是双引号引起的 0 个或若干个字符。
- 含义 : 字符常量相当于一个整型值(ASCII 值),可以参加表达式运算; 字符串常量代表一个地址值(该字符串在内存中存放位置)。
- 占内存大小:字符常量只占 2 个字节; 字符串常量占若干个字节。
⚠️ 注意 char 在 Java 中占两个字节。
字符型常量和字符串常量代码示例:
public class StringExample {
// 字符型常量
public static final char LETTER_A = 'A';
// 字符串常量
public static final String GREETING_MESSAGE = "Hello, world!";
public static void main(String[] args) {
System.out.println("字符型常量占用的字节数为:"+Character.BYTES);
System.out.println("字符串常量占用的字节数为:"+GREETING_MESSAGE.getBytes().length);
}
}输出:
字符型常量占用的字节数为:2
字符串常量占用的字节数为:13📝 通俗解释
- 字符型 ('a'):单引号,只能装 一个 字,是基本类型(本质是数字)。
- 字符串 ("abc"):双引号,能装 一串 字,是对象(引用类型),占内存大。
就像“一粒米”和“一袋米”的区别。
方法
什么是方法的返回值?方法有哪几种类型?
方法的返回值 是指我们获取到的某个方法体中的代码执行后产生的结果!(前提是该方法可能产生结果)。返回值的作用是接收出结果,使得它可以用于其他的操作!
我们可以按照方法的返回值和参数类型将方法分为下面这几种:
1、无参数无返回值的方法
public void f1() {
//......
}
// 下面这个方法也没有返回值,虽然用到了 return
public void f(int a) {
if (...) {
// 表示结束方法的执行,下方的输出语句不会执行
return;
}
System.out.println(a);
}2、有参数无返回值的方法
public void f2(Parameter 1, ..., Parameter n) {
//......
}3、有返回值无参数的方法
public int f3() {
//......
return x;
}4、有返回值有参数的方法
public int f4(int a, int b) {
return a * b;
}📝 通俗解释
方法就是“办事处”。
- 参数:你交给办事处的材料。
- 返回值:办事处办完事后给你的结果(如盖好章的文件)。
- void:有的办事处(方法)只管办事(如打印一下),不给你任何东西,这就是无返回值。
静态方法为什么不能调用非静态成员?
这个需要结合 JVM 的相关知识,主要原因如下:
- 静态方法是属于类的,在类加载的时候就会分配内存,可以通过类名直接访问。而非静态成员属于实例对象,只有在对象实例化之后才存在,需要通过类的实例对象去访问。
- 在类的非静态成员不存在的时候静态方法就已经存在了,此时调用在内存中还不存在的非静态成员,属于非法操作。
public class Example {
// 定义一个字符型常量
public static final char LETTER_A = 'A';
// 定义一个字符串常量
public static final String GREETING_MESSAGE = "Hello, world!";
public static void main(String[] args) {
// 输出字符型常量的值
System.out.println("字符型常量的值为:" + LETTER_A);
// 输出字符串常量的值
System.out.println("字符串常量的值为:" + GREETING_MESSAGE);
}
}📝 通俗解释
- 静态方法(如
main)是“模具级别”的功能,不用造出对象就能用。- 非静态成员(实例变量)是“成品级别”的数据,只有造出对象后才存在。
你在画图纸(静态)的时候,没法去摸真实的零件(非静态),因为零件还没造出来呢!所以静态方法里不能直接用非静态成员。
⭐️静态方法和实例方法有何不同?
1、调用方式
在外部调用静态方法时,可以使用 类名.方法名 的方式,也可以使用 对象.方法名 的方式,而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象 。
不过,需要注意的是一般不建议使用 对象.方法名 的方式来调用静态方法。这种方式非常容易造成混淆,静态方法不属于类的某个对象而是属于这个类。
因此,一般建议使用 类名.方法名 的方式来调用静态方法。
public class Person {
public void method() {
//......
}
public static void staicMethod(){
//......
}
public static void main(String[] args) {
Person person = new Person();
// 调用实例方法
person.method();
// 调用静态方法
Person.staicMethod()
}
}2、访问类成员是否存在限制
静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),不允许访问实例成员(即实例成员变量和实例方法),而实例方法不存在这个限制。
📝 通俗解释
- 静态方法 (
static):工具函数,比如Math.abs()。不需要new对象,直接类名.方法()就能用。- 实例方法:对象行为,比如
person.eat()。必须先new一个对象,然后让这个对象去执行。静态方法像“公共电话”,谁都能打;实例方法像“私人手机”,得先有手机(对象)才能打。
⭐️重载和重写有什么区别?
重载就是同样的一个方法能够根据输入数据的不同,做出不同的处理
重写就是当子类继承自父类的相同方法,输入数据一样,但要做出有别于父类的响应时,你就要覆盖父类方法
重载
发生在同一个类中(或者父类和子类之间),方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。
《Java 核心技术》这本书是这样介绍重载的:
如果多个方法(比如
StringBuilder的构造方法)有相同的名字、不同的参数, 便产生了重载。StringBuilder sb = new StringBuilder(); StringBuilder sb2 = new StringBuilder("HelloWorld");编译器必须挑选出具体执行哪个方法,它通过用各个方法给出的参数类型与特定方法调用所使用的值类型进行匹配来挑选出相应的方法。 如果编译器找不到匹配的参数, 就会产生编译时错误, 因为根本不存在匹配, 或者没有一个比其他的更好(这个过程被称为重载解析(overloading resolution))。
Java 允许重载任何方法, 而不只是构造器方法。
综上:重载就是同一个类中多个同名方法根据不同的传参来执行不同的逻辑处理。
重写
重写发生在运行期,是子类对父类的允许访问的方法的实现过程进行重新编写。
- 方法名、参数列表必须相同,子类方法返回值类型应比父类方法返回值类型更小或相等,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。
- 如果父类方法访问修饰符为
private/final/static则子类就不能重写该方法,但是被static修饰的方法能够被再次声明。 - 构造方法无法被重写
总结
综上:重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变。
| 区别点 | 重载 (Overloading) | 重写 (Overriding) |
|---|---|---|
| 发生范围 | 同一个类中。 | 父类与子类之间(存在继承关系)。 |
| 方法签名 | 方法名必须相同,但参数列表必须不同(参数的类型、个数或顺序至少有一项不同)。 | 方法名、参数列表必须完全相同。 |
| 返回类型 | 与返回值类型无关,可以任意修改。 | 子类方法的返回类型必须与父类方法的返回类型相同,或者是其子类。 |
| 访问修饰符 | 与访问修饰符无关,可以任意修改。 | 子类方法的访问权限不能低于父类方法的访问权限。(public > protected > default > private) |
| 绑定时期 | 编译时绑定或称静态绑定 | 运行时绑定 (Run-time Binding) 或称动态绑定 |
方法的重写要遵循“两同两小一大”(以下内容摘录自《疯狂 Java 讲义》,issue#892 ):
- “两同”即方法名相同、形参列表相同;
- “两小”指的是子类方法返回值类型应比父类方法返回值类型更小或相等,子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等;
- “一大”指的是子类方法的访问权限应比父类方法的访问权限更大或相等。
⭐️ 关于 重写的返回值类型 这里需要额外多说明一下,上面的表述不太清晰准确:如果方法的返回类型是 void 和基本数据类型,则返回值重写时不可修改。但是如果方法的返回值是引用类型,重写时是可以返回该引用类型的子类的。
public class Hero {
public String name() {
return "超级英雄";
}
}
public class SuperMan extends Hero{
@Override
public String name() {
return "超人";
}
public Hero hero() {
return new Hero();
}
}
public class SuperSuperMan extends SuperMan {
@Override
public String name() {
return "超级超级英雄";
}
@Override
public SuperMan hero() {
return new SuperMan();
}
}📝 通俗解释
- 重载 (Overload):“一词多义”。同一个类里,方法名相同,但参数不同。比如“洗”,可以“洗衣服”、“洗车”、“洗澡”。虽然都叫洗,但洗的东西不一样。
- 重写 (Override):“父业子承”。子类继承父类,但觉得父类的方法不好用,自己重新写一个。比如爸爸会“开车”(开拖拉机),儿子继承后也“开车”,但改成了(开法拉利)。方法名、参数都得一样,只是实现变了。
什么是可变长参数?
从 Java5 开始,Java 支持定义可变长参数,所谓可变长参数就是允许在调用方法时传入不定长度的参数。就比如下面这个方法就可以接受 0 个或者多个参数。
public static void method1(String... args) {
//......
}另外,可变参数只能作为函数的最后一个参数,但其前面可以有也可以没有任何其他参数。
public static void method2(String arg1, String... args) {
//......
}遇到方法重载的情况怎么办呢?会优先匹配固定参数还是可变参数的方法呢?
答案是会优先匹配固定参数的方法,因为固定参数的方法匹配度更高。
我们通过下面这个例子来证明一下。
/**
* 微信搜 JavaGuide 回复"“学习”突击"即可免费领取个人原创的 Java “学习”手册
*
* @author Guide哥
* @date 2021/12/13 16:52
**/
public class VariableLengthArgument {
public static void printVariable(String... args) {
for (String s : args) {
System.out.println(s);
}
}
public static void printVariable(String arg1, String arg2) {
System.out.println(arg1 + arg2);
}
public static void main(String[] args) {
printVariable("a", "b");
printVariable("a", "b", "c", "d");
}
}输出:
ab
a
b
c
d另外,Java 的可变参数编译后实际会被转换成一个数组,我们看编译后生成的 class文件就可以看出来了。
public class VariableLengthArgument {
public static void printVariable(String... args) {
String[] var1 = args;
int var2 = args.length;
for(int var3 = 0; var3 < var2; ++var3) {
String s = var1[var3];
System.out.println(s);
}
}
// ......
}📝 通俗解释
可变长参数 (String... args) 就像是“无限背包”。
调用方法时,你想传 1 个、2 个、100 个参数,甚至不传都可以。
Java 内部会自动把这些参数打包成一个 数组 传进去。方便是方便,但记得它必须放在参数列表的 最后。
参考
- What is the difference between JDK and JRE?:https://stackoverflow.com/questions/1906445/what-is-the-difference-between-jdk-and-jre
- Oracle vs OpenJDK:https://www.educba.com/oracle-vs-openjdk/
- Differences between Oracle JDK and OpenJDK:https://stackoverflow.com/questions/22358071/differences-between-oracle-jdk-and-openjdk
- 彻底弄懂 Java 的移位操作符:https://juejin.cn/post/6844904025880526861