CopyOnWriteArrayList 源码分析
CopyOnWriteArrayList 简介
在 JDK1.5 之前,如果想要使用并发安全的 List 只能选择 Vector。而 Vector 是一种老旧的集合,已经被淘汰。Vector 对于增删改查等方法基本都加了 synchronized,这种方式虽然能够保证同步,但这相当于对整个 Vector 加上了一把大锁,使得每个方法执行的时候都要去获得锁,导致性能非常低下。
JDK1.5 引入了 Java.util.concurrent(JUC)包,其中提供了很多线程安全且并发性能良好的容器,其中唯一的线程安全 List 实现就是 CopyOnWriteArrayList 。关于java.util.concurrent 包下常见并发容器的总结,可以看我写的这篇文章:Java 常见并发容器总结 。
CopyOnWriteArrayList 到底有什么厉害之处?
📝 通俗解释:
以前的Vector就像一个只有一个窗口的银行,不管是存钱(写)还是查余额(读),所有人都得排队,效率很低。CopyOnWriteArrayList就像一个告示栏。大家都可以随时来看(读),不需要排队,怎么看都行。但是,如果管理员要贴新告示(写),他不会直接在原来的板子上涂改,而是先把板子上的内容复制一份到新的板子上,在新的板子上改好,然后迅速把旧板子换成新板子。
这样一来,看告示的人永远不会被干扰,读的效率极高。只有改告示的时候才需要“互斥”(不能两个管理员同时换板子)。
Copy-On-Write 的思想是什么?
📝 通俗解释:
“写时复制”(COW)的核心就是:要改数据,先拷一份。
想象你在编辑一份公司规章制度。
- 读:所有员工随时都可以看这份制度,互不影响。
- 写:你要修改时,不直接在原件上改,而是复印一份副本。
- 改:在副本上修改。
- 换:修改完后,发布新版,替换旧版。
优点:读操作完全不用锁,飞快。
缺点:
- 费内存:每次改都要复印全部内容(比如你有1万个元素,加1个,就得把这1万个都复制一遍)。
- 慢:复制过程耗时。
- 延迟:你改副本的时候,别人读的还是旧版本(最终一致性,不是实时一致性)。
初始化
📝 通俗解释:
这里的初始化很简单,就是准备那个“底层数组”。
- 无参构造:弄个空数组
Object[0]挂在那。- 有参构造:把你给的集合或数组里的东西,统统复制一份,做成一个新的数组挂在那。
就像是买了一个新的空书架,或者把旧书架的书搬到一个新书架上。
插入元素
📝 通俗解释:
这里的add操作是CopyOnWriteArrayList最大的特色,也是最“重”的操作。
想象你要在一个队伍末尾加一个人:
- 上锁:先拿个大喇叭喊“所有人暂停,我要调整队伍”,防止别人同时也来插队(保证写安全)。
- 复制:找一块更大的空地(长度+1),把原来队伍里的人一个一个挪过去。
- 添加:把新来的人站到新队伍的最后一位。
- 替换:宣布“新队伍才是正式队伍”,原来的地盘不要了。
- 解锁:完事。
这里的代价就是:哪怕只是加一个人,也得把全队人搬一次家。所以千万别在循环里一个个add,那样简直是灾难!
读取元素
对于大部分业务场景来说,读取操作往往是远大于写入操作的。由于读取操作不会对原有数据进行修改,因此,对于每次读取都进行加锁其实是一种资源浪费。相比之下,我们应该允许多个线程同时访问 List 的内部数据,毕竟对于读取操作来说是安全的。
这种思路与 ReentrantReadWriteLock 读写锁的设计思想非常类似,即读读不互斥、读写互斥、写写互斥(只有读读不互斥)。CopyOnWriteArrayList 更进一步地实现了这一思想。为了将读操作性能发挥到极致,CopyOnWriteArrayList 中的读取操作是完全无需加锁的。更加厉害的是,写入操作也不会阻塞读取操作,只有写写才会互斥。这样一来,读操作的性能就可以大幅度提升。
CopyOnWriteArrayList 线程安全的核心在于其采用了 写时复制(Copy-On-Write) 的策略,从 CopyOnWriteArrayList 的名字就能看出了。
Copy-On-Write 的思想是什么?
CopyOnWriteArrayList名字中的“Copy-On-Write”即写时复制,简称 COW。
下面是维基百科对 Copy-On-Write 的介绍,介绍的挺不错:
写入时复制(英语:Copy-on-write,简称 COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
这里再以 CopyOnWriteArrayList为例介绍:当需要修改( add,set、remove 等操作) CopyOnWriteArrayList 的内容时,不会直接修改原数组,而是会先创建底层数组的副本,对副本数组进行修改,修改完之后再将修改后的数组赋值回去,这样就可以保证写操作不会影响读操作了。
可以看出,写时复制机制非常适合读多写少的并发场景,能够极大地提高系统的并发性能。
不过,写时复制机制并不是银弹,其依然存在一些缺点,下面列举几点:
- 内存占用:每次写操作都需要复制一份原始数据,会占用额外的内存空间,在数据量比较大的情况下,可能会导致内存资源不足。
- 写操作开销:每一次写操作都需要复制一份原始数据,然后再进行修改和替换,所以写操作的开销相对较大,在写入比较频繁的场景下,性能可能会受到影响。
- 数据一致性问题:修改操作不会立即反映到最终结果中,还需要等待复制完成,这可能会导致一定的数据一致性问题。
- ……
📝 通俗解释:
- 核心机制:读写分离。读的时候读旧墙上的告示,写的时候在家里画好新告示,然后出去把旧墙换成新墙。
- 适用场景:读多写少。比如白名单、配置信息、商品类目等。
- 代价:
- 内存:因为要复制,所以内存占用翻倍(短时间内)。
- 一致性:写完的一瞬间,可能别的线程还在读旧数据(最终一致性)。
CopyOnWriteArrayList 源码分析
这里以 JDK1.8 为例,分析一下 CopyOnWriteArrayList 的底层核心源码。
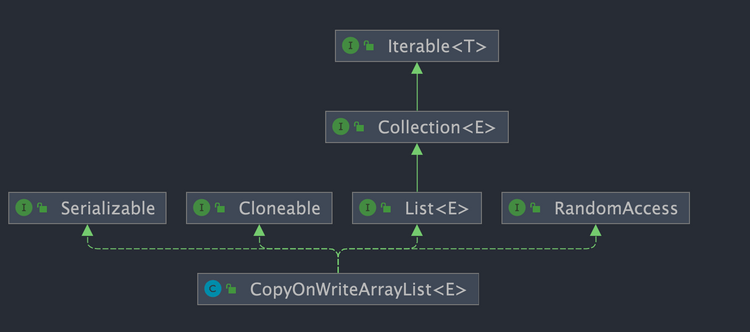
CopyOnWriteArrayList 的类定义如下:
public class CopyOnWriteArrayList<E>
extends Object
implements List<E>, RandomAccess, Cloneable, Serializable
{
//...
}CopyOnWriteArrayList 实现了以下接口:
List: 表明它是一个列表,支持添加、删除、查找等操作,并且可以通过下标进行访问。RandomAccess:这是一个标志接口,表明实现这个接口的List集合是支持 快速随机访问 的。Cloneable:表明它具有拷贝能力,可以进行深拷贝或浅拷贝操作。Serializable: 表明它可以进行序列化操作,也就是可以将对象转换为字节流进行持久化存储或网络传输,非常方便。
初始化
📝 通俗解释:
源码里的构造方法就是干两件事:
- 无参:直接给个空数组
Object[0]。- 有参:不管你传什么(集合还是数组),我都用
Arrays.copyOf把你的东西拷贝一份,变成我的新数组。
确保我的数组是我自己独有的,别人改不了。
CopyOnWriteArrayList 中有一个无参构造函数和两个有参构造函数。
// 创建一个空的 CopyOnWriteArrayList
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
// 按照集合的迭代器返回的顺序创建一个包含指定集合元素的 CopyOnWriteArrayList
public CopyOnWriteArrayList(Collection<? extends E> c) {
Object[] elements;
if (c.getClass() == CopyOnWriteArrayList.class)
elements = ((CopyOnWriteArrayList<?>)c).getArray();
else {
elements = c.toArray();
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elements.getClass() != Object[].class)
elements = Arrays.copyOf(elements, elements.length, Object[].class);
}
setArray(elements);
}
// 创建一个包含指定数组的副本的列表
public CopyOnWriteArrayList(E[] toCopyIn) {
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}插入元素
📝 通俗解释:
源码验证了之前的说法,add就是“费力”的操作:
- lock.lock():先加锁,保证只有一个线程在做“搬家”这件大事。
- getArray():拿到旧数组。
- Arrays.copyOf():创建新数组(长度+1),并把旧数据拷过去。
- newElements[len] = e:把新元素放在最后。
- setArray():把家里的钥匙换成新房子的钥匙。
- lock.unlock():解锁。
CopyOnWriteArrayList 的 add()方法有三个版本:
add(E e):在CopyOnWriteArrayList的尾部插入元素。add(int index, E element):在CopyOnWriteArrayList的指定位置插入元素。addIfAbsent(E e):如果指定元素不存在,那么添加该元素。如果成功添加元素则返回 true。
这里以add(E e)为例进行介绍:
// 插入元素到 CopyOnWriteArrayList 的尾部
public boolean add(E e) {
final ReentrantLock lock = this.lock;
// 加锁
lock.lock();
try {
// 获取原来的数组
Object[] elements = getArray();
// 原来数组的长度
int len = elements.length;
// 创建一个长度+1的新数组,并将原来数组的元素复制给新数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 元素放在新数组末尾
newElements[len] = e;
// array指向新数组
setArray(newElements);
return true;
} finally {
// 解锁
lock.unlock();
}
}从上面的源码可以看出:
add方法内部用到了ReentrantLock加锁,保证了同步,避免了多线程写的时候会复制出多个副本出来。锁被修饰保证了锁的内存地址肯定不会被修改,并且,释放锁的逻辑放在finally中,可以保证锁能被释放。CopyOnWriteArrayList通过复制底层数组的方式实现写操作,即先创建一个新的数组来容纳新添加的元素,然后在新数组中进行写操作,最后将新数组赋值给底层数组的引用,替换掉旧的数组。这也就证明了我们前面说的:CopyOnWriteArrayList线程安全的核心在于其采用了 写时复制(Copy-On-Write) 的策略。- 每次写操作都需要通过
Arrays.copyOf复制底层数组,时间复杂度是 O(n) 的,且会占用额外的内存空间。因此,CopyOnWriteArrayList适用于读多写少的场景,在写操作不频繁且内存资源充足的情况下,可以提升系统的性能表现。 CopyOnWriteArrayList中并没有类似于ArrayList的grow()方法扩容的操作。
Arrays.copyOf方法的时间复杂度是 O(n),其中 n 表示需要复制的数组长度。因为这个方法的实现原理是先创建一个新的数组,然后将源数组中的数据复制到新数组中,最后返回新数组。这个方法会复制整个数组,因此其时间复杂度与数组长度成正比,即 O(n)。值得注意的是,由于底层调用了系统级别的拷贝指令,因此在实际应用中这个方法的性能表现比较优秀,但是也需要注意控制复制的数据量,避免出现内存占用过高的情况。
读取元素
📝 通俗解释:
源码展示了“省力”的操作:
- getArray():直接拿到当前的数组引用。
- a[index]:直接取值。
全程没有锁!哪怕这个时候别的线程正在疯狂add,它也只是在操作新数组,不影响我读旧数组。这就叫“弱一致性”(读到的可能是旧数据,但性能极高)。
CopyOnWriteArrayList 的读取操作是基于内部数组 array 并没有发生实际的修改,因此在读取操作时不需要进行同步控制和锁操作,可以保证数据的安全性。这种机制下,多个线程可以同时读取列表中的元素。
// 底层数组,只能通过getArray和setArray方法访问
private transient volatile Object[] array;
public E get(int index) {
return get(getArray(), index);
}
final Object[] getArray() {
return array;
}
private E get(Object[] a, int index) {
return (E) a[index];
}不过,get方法是弱一致性的,在某些情况下可能读到旧的元素值。
get(int index)方法是分两步进行的:
- 通过
getArray()获取当前数组的引用; - 直接从数组中获取下标为 index 的元素。
这个过程并没有加锁,所以在并发环境下可能出现如下情况:
- 线程 1 调用
get(int index)方法获取值,内部通过getArray()方法获取到了 array 属性值; - 线程 2 调用
CopyOnWriteArrayList的add、set、remove等修改方法时,内部通过setArray方法修改了array属性的值; - 线程 1 还是从旧的
array数组中取值。
获取列表中元素的个数
📝 通俗解释:
因为数组每次都是刚刚好装满(copy 的时候长度就是+1),没有“容量”和“实际大小”的区别。
所以array.length就是size。
public int size() {
return getArray().length;
}CopyOnWriteArrayList中的array数组每次复制都刚好能够容纳下所有元素,并不像ArrayList那样会预留一定的空间。因此,CopyOnWriteArrayList中并没有size属性CopyOnWriteArrayList的底层数组的长度就是元素个数,因此size()方法只要返回数组长度就可以了。
删除元素
📝 通俗解释:
删除和添加类似,也是“搬家”。
- 上锁。
- 复制:创建一个比原来短1截的新数组。
- 搬运:把要删除的那个元素前面的搬过去,再把它后面的搬过去(跳过它)。
- 替换:数组指向新的。
- 解锁。
同样,这也是个大工程,能少做就少做。
判断元素是否存在
CopyOnWriteArrayList删除元素相关的方法一共有 4 个:
remove(int index):移除此列表中指定位置上的元素。将任何后续元素向左移动(从它们的索引中减去 1)。boolean remove(Object o):删除此列表中首次出现的指定元素,如果不存在该元素则返回 false。boolean removeAll(Collection<?> c):从此列表中删除指定集合中包含的所有元素。void clear():移除此列表中的所有元素。
这里以remove(int index)为例进行介绍:
public E remove(int index) {
// 获取可重入锁
final ReentrantLock lock = this.lock;
// 加锁
lock.lock();
try {
//获取当前array数组
Object[] elements = getArray();
// 获取当前array长度
int len = elements.length;
//获取指定索引的元素(旧值)
E oldValue = get(elements, index);
int numMoved = len - index - 1;
// 判断删除的是否是最后一个元素
if (numMoved == 0)
// 如果删除的是最后一个元素,直接复制该元素前的所有元素到新的数组
setArray(Arrays.copyOf(elements, len - 1));
else {
// 分段复制,将index前的元素和index+1后的元素复制到新数组
// 新数组长度为旧数组长度-1
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
//将新数组赋值给array引用
setArray(newElements);
}
return oldValue;
} finally {
// 解锁
lock.unlock();
}
}判断元素是否存在
📝 通俗解释:
contains方法也很简单粗暴:
- getArray():拿到当前数组。
- 遍历:从头到尾找一遍。
- 结果:找到了返回 true,找不到返回 false。
同样,因为它没有加锁,所以可能你刚检查完“没有”,下一秒别人就加进去了。但大多数时候,我们只关心“检查的那一刻”有没有。
CopyOnWriteArrayList提供了两个用于判断指定元素是否在列表中的方法:
contains(Object o):判断是否包含指定元素。containsAll(Collection<?> c):判断是否保证指定集合的全部元素。
// 判断是否包含指定元素
public boolean contains(Object o) {
//获取当前array数组
Object[] elements = getArray();
//调用index尝试查找指定元素,如果返回值大于等于0,则返回true,否则返回false
return indexOf(o, elements, 0, elements.length) >= 0;
}
// 判断是否保证指定集合的全部元素
public boolean containsAll(Collection<?> c) {
//获取当前array数组
Object[] elements = getArray();
//获取数组长度
int len = elements.length;
//遍历指定集合
for (Object e : c) {
//循环调用indexOf方法判断,只要有一个没有包含就直接返回false
if (indexOf(e, elements, 0, len) < 0)
return false;
}
//最后表示全部包含或者制定集合为空集合,那么返回true
return true;
}CopyOnWriteArrayList 常用方法测试
📝 通俗解释:
这部分代码演示了基本用法。
只要记住:
add/remove/set:虽然用法和 ArrayList 一样,但背后都在疯狂复制数组,悠着点用。get/iterator:放心用,飞快。
代码:
// 创建一个 CopyOnWriteArrayList 对象
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
// 向列表中添加元素
list.add("Java");
list.add("Python");
list.add("C++");
System.out.println("初始列表:" + list);
// 使用 get 方法获取指定位置的元素
System.out.println("列表第二个元素为:" + list.get(1));
// 使用 remove 方法删除指定元素
boolean result = list.remove("C++");
System.out.println("删除结果:" + result);
System.out.println("列表删除元素后为:" + list);
// 使用 set 方法更新指定位置的元素
list.set(1, "Golang");
System.out.println("列表更新后为:" + list);
// 使用 add 方法在指定位置插入元素
list.add(0, "PHP");
System.out.println("列表插入元素后为:" + list);
// 使用 size 方法获取列表大小
System.out.println("列表大小为:" + list.size());
// 使用 removeAll 方法删除指定集合中所有出现的元素
result = list.removeAll(List.of("Java", "Golang"));
System.out.println("批量删除结果:" + result);
System.out.println("列表批量删除元素后为:" + list);
// 使用 clear 方法清空列表中所有元素
list.clear();
System.out.println("列表清空后为:" + list);输出:
列表更新后为:[Java, Golang]
列表插入元素后为:[PHP, Java, Golang]
列表大小为:3
批量删除结果:true
列表批量删除元素后为:[PHP]
列表清空后为:[]